Chuẩn hóa dữ liệu là quá trình tổ chức và cấu trúc lại cơ sở dữ liệu nhằm loại bỏ dư thừa, tránh sai sót khi thêm, xóa, cập nhật dữ liệu. Mục tiêu chính là đảm bảo dữ liệu nhất quán, dễ quản lý và nâng cao hiệu quả lưu trữ.
I. Tại sao bạn cần quan tâm tới chuẩn hoá dữ liệu?
Bạn có biết rằng theo một bài báo của Harvard Business Review, dữ liệu kém chất lượng khiến nước Mỹ thiệt hại tới 3 nghìn tỷ đô mỗi năm?
Một phần lớn của vấn đề này bắt nguồn từ việc cấu trúc cơ sở dữ liệu (database) được thiết kế kém – thiếu nhất quán, dư thừa, và khó quản lý. Và đó chính là lý do tại sao bạn cần hiểu và ứng dụng khái niệm data normalization– chuẩn hoá dữ liệu.

Trong bài này, ACE sẽ giúp bạn:
- Nắm rõ khái niệm về data normalization
- Hiểu 3 lỗi lớn thường gặp khi không chuẩn hoá dữ liệu
- Biết cách khắc phục thông qua việc tách bảng và sử dụng normal forms
II. Data Normalization là gì?
Hiểu một cách đơn giản, Data Normalization là quy trình tổ chức lại dữ liệu để đảm bảo:
- Không bị dư thừa (redundant)
- Không bị lỗi khi cập nhật (update errors)
- Dễ mở rộng và truy vấn (scalable, maintainable)
Bạn có thể nghĩ: “Chẳng phải chỉ cần đưa dữ liệu vào bảng có hàng và cột là đủ rồi sao?”
Ví dụ, ta có một bảng như sau:

Thoạt nhìn thì bảng có vẻ ổn – có đầy đủ cột và dữ liệu. Nhưng hãy để ý:
- Tên sản phẩm, danh mục, tên cửa hàng, và địa chỉ bị lặp lại rất nhiều lần.
- Điều này dẫn tới: tốn dung lượng, khó cập nhật, và dễ sai sót.

III. 3 vấn đề phổ biến khi không chuẩn hóa dữ liệu
Vấn đề 1. Dữ liệu dư thừa (Data Redundancy)

Ở bảng trên, bạn có thể thấy tên sản phẩm, danh mục, tên cửa hàng, và địa chỉ cửa hàng bị lặp lại nhiều lần.
Điều này dẫn đến:
- Tốn dung lượng lưu trữ
- Khó kiểm soát
- Và đặt ra câu hỏi: Có thật sự cần phải lặp lại tất cả các cột này không?
Câu trả lời là không. Mình sẽ cho bạn thấy cách loại bỏ sự dư thừa này mà không làm mất dữ liệu.
Vấn đề 2. Lỗi khi cập nhật (Update Anomaly)

Giả sử bạn cần cập nhật địa chỉ cửa hàng – ví dụ như “Apple Store” chuyển sang một địa chỉ mới. Nếu dữ liệu lặp lại nhiều nơi, bạn phải cập nhật tất cả các dòng có chứa thông tin đó. Và trong một dataset có hàng ngàn, hàng triệu dòng, việc bỏ sót là điều rất dễ xảy ra. Kết quả? Dữ liệu không còn nhất quán.
Trong kỹ thuật, người ta gọi đây là Update Anomaly – lỗi xảy ra khi việc cập nhật không đồng bộ trên toàn bộ dữ liệu. Nếu bạn chưa quen với từ “anomaly”, bạn có thể hiểu đơn giản là một sự cố hay vấn đề sai lệch trong hệ thống.
Vấn đề 3. Lỗi khi chèn dữ liệu mới (Insertion Anomaly)

Giờ giả sử bạn muốn thêm một cửa hàng mới – ví dụ như “Miami Store”. Nhưng vì chưa có đơn hàng nào từ cửa hàng này, bạn lại buộc phải tạo một dòng mới trong bảng – với một số cột để trống.
Kết quả:
- Dữ liệu bị thiếu, do có nhiều giá trị null,
- Và tệ hơn, nó có thể bị hiểu nhầm là dữ liệu lỗi.
Đây là một ví dụ điển hình của Insertion Anomaly – lỗi khi bạn không thể thêm dữ liệu mới một cách gọn gàng do cấu trúc bảng không hợp lý.
Vấn đề 4. Lỗi khi xoá dữ liệu (Deletion Anomaly)

Một lỗi khác rất nguy hiểm: xoá dữ liệu ngoài ý muốn.
Ví dụ: Bạn xoá một dòng đơn hàng có chứa sản phẩm AirPods. Nhưng nếu tất cả thông tin về sản phẩm này – tên, danh mục – đều nằm trong dòng đó, thì việc xoá dòng đó đồng nghĩa với việc: Toàn bộ thông tin về AirPods biến mất khỏi database.
Bạn chỉ định xoá đơn hàng, nhưng lại xoá luôn cả sản phẩm.
Đó chính là Deletion Anomaly – lỗi phát sinh khi việc xoá một dòng dữ liệu kéo theo mất luôn dữ liệu quan trọng mà bạn không có ý định xoá
IV. Giải pháp: Chuẩn hoá dữ liệu (Database Normalization)
Sau khi chúng ta đã xác định được những lỗi nghiêm trọng trong cách tổ chức dữ liệu ban đầu – từ dữ liệu bị lặp, lỗi cập nhật, lỗi thêm mới, đến lỗi xoá dữ liệu – rõ ràng là chúng ta cần một cấu trúc tốt hơn. Và đó là lúc data normalization thực sự phát huy tác dụng.
Vậy Normal Forms là gì?
Để chuẩn hoá dữ liệu một cách hệ thống, chúng ta sử dụng một bộ quy tắc gọi là Normal Forms – tức là các “dạng chuẩn” trong thiết kế cơ sở dữ liệu.
Điều quan trọng là: Bạn phải đạt được dạng chuẩn thứ nhất (1NF) trước, rồi mới tiến lên 2NF, sau đó mới đến 3NF. Không thể nhảy cóc.
Nếu dữ liệu đáp ứng quy tắc của 1NF, ta nói nó thuộc First Normal Form. Nếu tiếp tục thoả mãn các quy tắc của 2NF, nó thuộc Second Normal Form, và tương tự đến Third Normal Form – 3NF.
Nói đơn giản: Càng đạt chuẩn cao hơn, rủi ro lỗi trong dữ liệu càng thấp.

Và để bạn dễ hình dung, hãy tưởng tượng giống như các đai trong võ thuật:
- 1NF tương đương với đai vàng (mới nhập môn),
- 2NF là đai xanh dương (có nền tảng tốt hơn),
- Và 3NF là đai đen – cấp độ cao nhất trong nhóm cơ bản.
Tương tự, trong cơ sở dữ liệu:
Dữ liệu ở cấp chuẩn cao hơn = tổ chức tốt hơn = ít lỗi hơn.
V. First Normal Form (1NF) – Chuẩn hoá cấp độ 1
Quy tắc 1: Mỗi ô chỉ được chứa một giá trị duy nhất
Trong kỹ thuật, người ta gọi đó là giá trị nguyên tử (atomic value). Ví dụ, bạn có một bảng với cột “Sản phẩm” như sau:
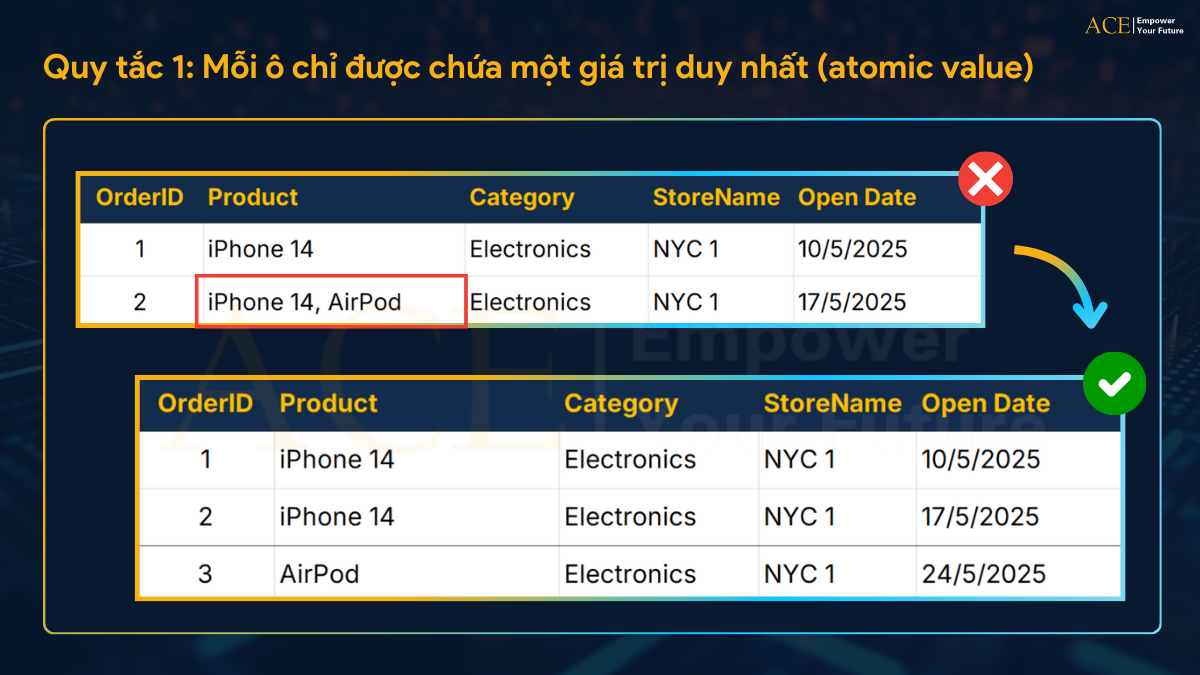
Ở đây, một ô chứa 2 sản phẩm – điều này vi phạm 1NF. Cách đúng là bạn phải tách thành 2 dòng, Mỗi ô chỉ chứa một giá trị duy nhất.
Quy tắc 2: Mỗi cột phải chứa cùng một kiểu dữ liệu

Ví dụ, ở cột “Giá tiền”:
- Dòng đầu là số nguyên (integer) với giá là $1,097,
- Dòng thứ hai là chuỗi chữ (string) là Free.
Điều này không chấp nhận được trong 1NF – vì cột này đang trộn kiểu dữ liệu.
Cách đúng là bạn phải chuyển “Free” thành số – ví dụ là 0, để cả cột đều dùng cùng một kiểu dữ liệu (số).
Quy tắc 3: Mỗi dòng dữ liệu phải có thể nhận diện duy nhất
Nghĩa là: Không được có hai dòng giống hệt nhau.
Ví dụ, nếu bạn có 2 dòng giống nhau hoàn toàn về tất cả các giá trị – thì hệ thống không thể phân biệt được.
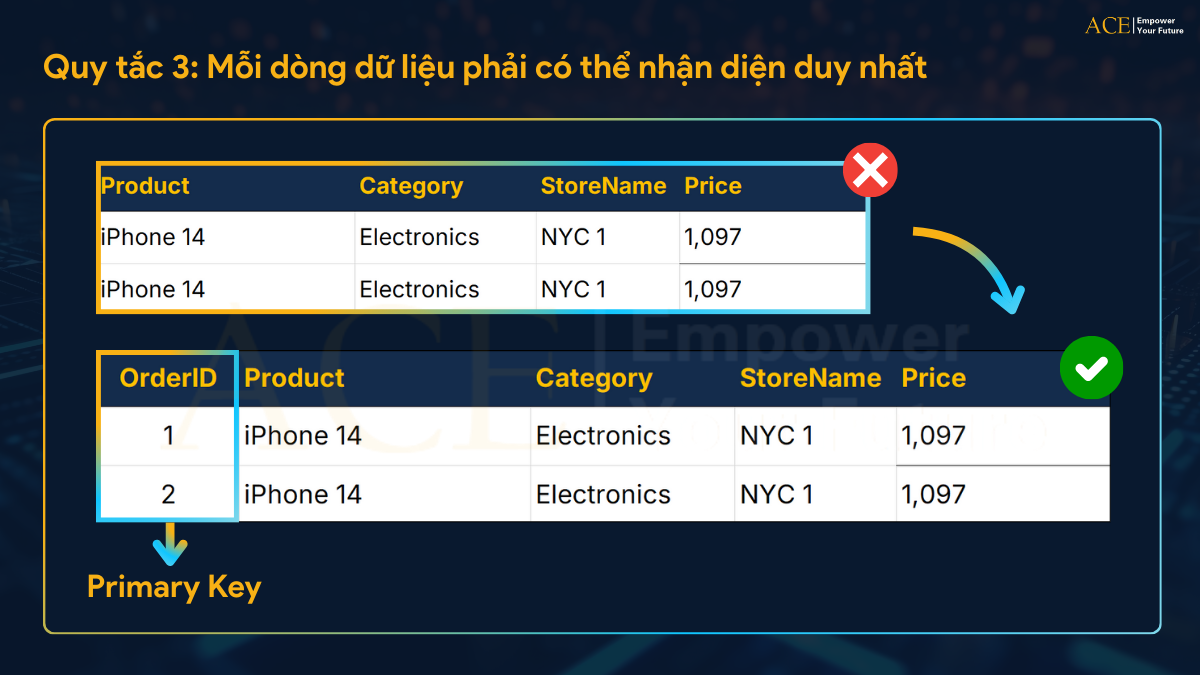
Cách giải quyết là bạn cần tạo một khoá chính (Primary Key).
- Primary Key là một cột (hoặc nhóm cột) có giá trị duy nhất cho từng dòng.
- Ví dụ: “Order ID” có thể là primary key vì mỗi đơn hàng đều có mã riêng.
- Các ví dụ khác: “Mã sinh viên”, “Số hộ chiếu” – những thông tin duy nhất và không trùng lặp.
VI. Second Normal Form (2NF) – Chuẩn hóa cấp độ 2
Sau khi dữ liệu của bạn đã đạt chuẩn First Normal Form (1NF), bạn mới được phép chuyển sang bước tiếp theo – đó là Second Normal Form (2NF).
Bạn không thể “nhảy cóc” lên đai xanh nếu chưa có đai vàng – cũng giống như không thể áp dụng 2NF nếu bảng chưa đạt 1NF.

Quy tắc chính của 2NF
Every non-key column must depend on the whole primary key
Mọi cột không thuộc khoá chính phải phụ thuộc vào toàn bộ khoá chính
Nghe có vẻ hơi rối phải không? Để mình giải thích từng bước:
Phân tích một ví dụ sai
Giả sử bảng dữ liệu của bạn có cấu trúc như sau:

Trong bảng này:
- Khoá chính là
Order ID + Product, vì một đơn hàng có thể chứa nhiều sản phẩm. - Nhưng để xem dữ liệu có đạt 2NF không, ta cần hỏi:
Liệu cột “Price” và “Category” có phụ thuộc hoàn toàn vào Order ID + Product không?
Câu trả lời là không.
- Giá sản phẩm không phụ thuộc vào mã đơn hàng (
Order ID), - Nó chỉ phụ thuộc vào Product.
Tương tự, “Tai nghe” là Category của AirPods, không liên quan gì đến đơn hàng cụ thể cả.
Đây là lỗi phổ biến trong vi phạm 2NF – khi một cột phụ thuộc vào một phần của khoá chính, thay vì toàn bộ.
Cách khắc phục lỗi để đạt chuẩn 2NF
Bạn cần tách bảng ra thành 2 bảng nhỏ hơn:

| 1. Một bảng lưu thông tin đơn hàng Orders Table – với mỗi dòng là một sản phẩm trong một đơn hàng: | 2. Một bảng riêng chứa thông tin chi tiết về từng sản phẩm – Product Table: |
 | |
Hãy nhớ lại những vấn đề lớn mà chúng ta từng phân tích khi dữ liệu không được tổ chức đúng cách:
- Update anomaly – lỗi khi cập nhật thông tin ở nhiều nơi và không đồng nhất;
- Insertion anomaly – lỗi khi muốn thêm dữ liệu nhưng cấu trúc bảng lại gây cản trở;
- Deletion anomaly – lỗi khi xoá một dòng nhưng vô tình làm mất thông tin cần giữ;
- Và lưu trữ lãng phí – cùng một thông tin bị lặp đi lặp lại trong hàng trăm, hàng ngàn dòng.
Tất cả những vấn đề này đều được giải quyết phần lớn nhờ vào việc chuẩn hoá dữ liệu, đặc biệt là khi bạn áp dụng Second Normal Form (2NF) đúng cách.
Một nguyên tắc cốt lõi cần nhớ: Mỗi mẩu thông tin chỉ nên hiện hữu ở duy nhất một nơi trong hệ thống.
Khi bạn đảm bảo nguyên tắc này, bạn sẽ:
- Giảm thiểu rủi ro lỗi
- Dễ dàng cập nhật, bảo trì
- Và giữ cho dữ liệu luôn sạch, rõ ràng, nhất quán
VII. Third Normal Form (3NF) – Chuẩn hóa cấp độ 3
Chúng ta đã đi qua:
- 1NF – loại bỏ dữ liệu lồng ghép, giữ giá trị nguyên tử;
- 2NF – đảm bảo mọi cột không khoá phải phụ thuộc toàn bộ khoá chính.
Giờ là lúc bước vào Third Normal Form – 3NF.
Yêu cầu chính của 3NF là:
No transitive dependencies (when a column depends on another non-key column, not directly on the primary key)
Không được có phụ thuộc bắc cầu giữa các dữ liệu.
Transitive Dependency
Phụ thuộc bắc cầu (transitive dependency) xảy ra khi:
- Một cột dữ liệu phụ thuộc vào một cột khác,
- Trong khi cột đó lại phụ thuộc vào khoá chính.
Tức là:
Dữ liệu A → phụ thuộc vào B → mà B lại phụ thuộc vào khoá chính → A phụ thuộc gián tiếp vào khoá chính.
Giả sử bạn có bảng sau:

Ở đây:
Productlà thông tin gắn với đơn hàng – nên nó phụ thuộc vàoOrder ID.Pricephụ thuộc vàoProduct– điều này vẫn ổn, vì giá sản phẩm cố định.- Nhưng
Categorylại không phụ thuộc trực tiếp vàoOrder ID, mà:
Category phụ thuộc vào Price → mà Price lại phụ thuộc vào Product.
→ Đây chính là phụ thuộc bắc cầu.
Kết quả là:
- Dữ liệu bị lặp lại (vì cùng một danh mục được ghi nhiều lần),
- Dễ phát sinh lỗi khi cập nhật (ví dụ sửa nhầm danh mục của sản phẩm).
Cách xử lý để đạt chuẩn 3NF
Để giải quyết phụ thuộc bắc cầu, bạn cần tách từng “lớp dữ liệu” ra thành các bảng riêng biệt. Ví dụ:
- Order Table – lưu thông tin đơn hàng (Order ID + Product);
- Product Table – lưu thông tin chi tiết sản phẩm (Product + Price);
- Pricing & Category Table – lưu thông tin danh mục gắn với từng sản phẩm.

Với cách tách này:
- Mỗi mẩu thông tin chỉ xuất hiện một lần duy nhất;
- Không có cột nào phụ thuộc gián tiếp kiểu bắc cầu;
- Cập nhật dữ liệu dễ dàng, không ảnh hưởng dây chuyền đến các bảng khác.
Ngoài 3NF còn có chuẩn nào nữa không?
Trên thực tế, ngoài 1NF, 2NF và 3NF, còn có các chuẩn hóa cao hơn như: 4NF (Fourth Normal Form), 5NF (Fifth Normal Form), và thậm chí cao hơn nữa.
Tuy nhiên, với hầu hết các ứng dụng thực tế trong doanh nghiệp – từ phân tích dữ liệu cho đến xây dựng hệ thống – 3NF đã được xem là cấp độ chuẩn hoá cao nhất cần thiết.
VIII. Thành thạo Power BI – phân tích dữ liệu cùng ACE Academy
Power BI đang ngày càng phổ biến trong các doanh nghiệp hiện nay. Sở hữu cho mình kĩ năng phân tích và trực quan hóa dữ liệu trên Power BI sẽ giúp bạn nổi bật giữa hàng nghìn nhân sự khác. Nếu bạn là newbie và chưa biết phải bắt đầu từ đâu, tham khảo ngay khóa học Decision Data Analytics In Power BI. Với chương trình được thiết kế từ những chuyên gia đầu ngành, khóa học sẽ giúp bạn:
– Hiểu rõ tư duy Decision Analytics – biến dữ liệu thành công cụ hỗ trợ ra quyết định.
– Thành thạo Power BI: từ kết nối dữ liệu, xử lý, trực quan hóa đến xây dựng dashboard.
– Biết cách ứng dụng các mô hình phân tích (what-if, scenario, sensitivity analysis) để chọn giải pháp tối ưu.
– Thực hành trên case study & project thực tế giúp áp dụng ngay vào công việc.
– Hoàn thiện dashboard chuyên nghiệp làm portfolio cá nhân.
– Trang bị kỹ năng giải thích dữ liệu và storytelling để thuyết phục quản lý/khách hàng.
Tham gia ngay các khóa học data tại ACE để trở thành chuyên gia dữ liệu thành công

IX. FAQ – Câu hỏi thường gặp khi chuẩn hóa dữ liệu
Tại sao cần chuẩn hóa dữ liệu?
Có những mức chuẩn hóa dữ liệu nào?
1NF: Mỗi cột chỉ chứa giá trị nguyên tử.
2NF: Loại bỏ phụ thuộc một phần, khóa chính phải đầy đủ.
3NF: Loại bỏ phụ thuộc bắc cầu (transitive dependency).
Chuẩn hóa dữ liệu có nhược điểm gì không?
Chuẩn hóa dữ liệu khác gì phi chuẩn hóa (denormalization)?
Phi chuẩn hóa: Chấp nhận dư thừa dữ liệu để tăng tốc truy vấn, thường dùng trong hệ thống Big Data, OLAP












