Thống kê mô tả (Descriptive Statistics) là phương pháp thống kê dùng để tóm tắt, trình bày và mô tả các đặc điểm cơ bản của tập dữ liệu thông qua các chỉ số, bảng biểu và đồ thị. Phương pháp này giúp người phân tích nhanh chóng hiểu dữ liệu hiện tại, làm nền tảng cho các bước phân tích sâu hơn.
I. Thống kê mô tả (Descriptive statistics) là gì?
Descriptive Statistics – Thống kê mô tả là một phương pháp trong lĩnh vực thống kê dùng để tóm tắt, trình bày và mô tả các đặc điểm cơ bản của tập dữ liệu. Thay vì tập trung vào việc đưa ra kết luận hay dự đoán về các xu hướng hay quan hệ phức tạp giữa các biến số, thống kê mô tả giúp bạn có một cái nhìn rõ ràng và toàn diện hơn về dữ liệu hiện tại.

II. Tại sao dùng phương pháp thống kê mô tả (Descriptive statistics) trong phân tích dữ liệu?
Thống kê mô tả đóng vai trò vô cùng quan trọng trong phân tích dữ liệu. Đặc biệt khi bạn đang đối mặt với một lượng dữ liệu lớn và phức tạp. Dưới đây là những lý do bạn nên sử dụng phương pháp thống kê mô tả trong phân tích:
1.Tóm tắt dữ liệu một cách toàn diện và rõ ràng
Thay vì phải đối mặt với hàng loạt con số và biến số phức tạp, thống kê mô tả giúp bạn thu gọn dữ liệu thành những con số chính. Giúp nó trở nên dễ hiểu và có thể quản lý được. Bằng cách cung cấp một cái nhìn tổng quan thông qua các giá trị trung bình, trung vị, hoặc độ lệch chuẩn, bạn sẽ có thể nắm bắt nhanh chóng tình trạng chung của tập dữ liệu.
2. Xác định các khuôn mẫu và điểm bất thường
Thông qua thống kê mô tả, bạn có thể dễ dàng xác định các khuôn mẫu trong dữ liệu. Chẳng hạn như sự phân phối giá trị hay mức độ biến thiên. Ngoài ra, thống kê mô tả cũng giúp bạn nhận diện các giá trị ngoại lệ (outliers). Hoặc các biến số bất thường trong tập dữ liệu. Từ đó giúp định hướng cho các phân tích tiếp theo.
3. Dễ dàng hình dung và truyền đạt thông tin
Sử dụng các công cụ như biểu đồ hình hộp, biểu đồ tần suất hoặc biểu đồ phân tán giúp bạn hiểu rõ hơn về dữ liệu. Bên cạnh đó còn giúp truyền đạt thông tin một cách trực quan. Điều này đặc biệt quan trọng khi bạn cần báo cáo kết quả cho các bên liên quan hoặc nhóm của mình mà không cần phải đi vào những chi tiết phức tạp.
4. Tạo cơ sở cho các phương pháp phân tích phức tạp hơn
Trước khi bước vào những phân tích phức tạp như phân tích dự đoán (predictive analytics) hoặc phân tích tương quan (correlation analysis), việc áp dụng thống kê mô tả giúp bạn hiểu rõ về bản chất dữ liệu mình đang làm việc. Điều này giúp bạn xác định liệu dữ liệu có đủ chất lượng để áp dụng các phương pháp phân tích phức tạp hơn hay không. Đồng thời giúp giảm thiểu rủi ro đưa ra các kết luận sai lệch.
Thống kê mô tả là bước quan trọng đầu tiên trong quá trình phân tích dữ liệu. Nó giúp bạn có cái nhìn tổng quan về dữ liệu. Nhận diện được các khuôn mẫu cũng như những điểm bất thường. Đồng thời tạo cơ sở cho các phân tích phức tạp hơn. Việc sử dụng thống kê mô tả không chỉ giúp bạn quản lý và hiểu rõ dữ liệu mà còn giúp truyền đạt thông tin một cách hiệu quả và dễ dàng hơn.
Hãy cùng xem phương pháp Phân tích thống kê mô tả được ứng dụng như thế nào trong quá trình Tư vấn tại các công ty tư vấn hàng đầu BCG dưới đây.

III. Đặt ra giả thuyết
1. Khởi đầu với đánh giá và phân tích dữ liệu
Đôi khi, bạn sẽ phải đối mặt với cả núi dữ liệu. Chẳng hạn báo cáo doanh số hàng quý, biên lai, tốc độ tăng trưởng GDP của nhiều quốc gia.. Và bạn được yêu cầu phải đánh giá và phân tích đống dữ liệu này. Cũng có thể bạn là người phải xử lý dữ liệu của người khác. Sau đó cần kiểm tra xem liệu họ có hiểu được ý nghĩa của dữ liệu đó hay không.
Để bắt đầu đánh giá, phân tích dữ liệu, bạn sẽ cần phải tiến hành một cách có hệ thống. Đầu tiên, bạn cần đặt ra một giả thuyết, sử dụng nó làm cơ sở để kiểm tra công việc. Nếu không đặt ra giả thuyết, bạn sẽ mắc kẹt trong đống dữ liệu, không hoàn thành được công việc.
2. Giả thuyết trong phân tích dữ liệu
Bạn nên nghĩ rằng phân tích dữ liệu có thể giúp bạn có được cái nhìn sâu sắc về một hoặc nhiều vấn đề cụ thể. Tốt nhất bạn nên bắt đầu bằng việc đưa ra một giả thuyết rõ ràng, tóm gọn nó trong một mệnh đề, chứ đừng đặt ra một câu hỏi.
Ví dụ, bạn có dữ liệu doanh số bán hàng hàng năm của nhân viên kinh doanh trong công ty. Bạn nhận ra một số nhân viên nhận tiền thưởng cao hơn mang lại nhiều lợi ích cho công ty. Nhưng cũng có một số nhân viên chỉ nhận được mức lương cứng. Và bạn tự hỏi liệu việc thưởng thêm tiền cho nhân viên có thực sự hiệu quả hay không? Và sau đó bạn ghi lại những giả thuyết xuất hiện trong đầu mình ngay lúc đó.
Đó có thể là những giả thuyết sau:
H1: Nhân viên kinh doanh bán được nhiều hàng hơn khi được tiền thưởng.
H2: Doanh thu bán hàng tỷ lệ thuận với mức tăng tiền thưởng tiềm năng.
H3: Kết quả tăng doanh thu nhiều hơn hẳn chi phí tiền thưởng cho nhân viên.
3. Đừng sợ đưa ra giả thuyết
Những nhân viên mới hoặc nhân viên cấp dưới thường ngần ngại với việc đưa ra một giả thuyết. Họ sợ rằng nếu những giả thuyết này bị bác bỏ. Điều này sẽ ảnh hưởng xấu đến hình ảnh của họ. Họ có thể đưa ra những lý do đại loại như: “Tôi không muốn mạo hiểm đưa ra bất kỳ giả thuyết nào trước khi xem xét kỹ lưỡng các dữ liệu,” hay “Vẫn còn quá sớm để đưa ra bất kỳ điều gì.”
Chúng tôi hiểu điều đó, nhưng đây chỉ là giả thuyết, không phải câu trả lời hay một kết luận. Mục đích của việc đưa ra giả thuyết chính là sắp xếp và phân loại dữ liệu. Nếu không làm vậy, bạn sẽ chìm trong núi dữ liệu lộn xộn, không bao giờ tìm được lối ra. Bước này thậm chí còn quan trọng hơn nếu như bạn không phải là người phân tích dữ liệu, nhưng lại là người giải quyết vấn đề. Nếu ai đó trong nhóm của bạn hoặc một cố vấn đang chuẩn bị thực hiện công việc này, thì bạn thực sự nên tham gia vào quá trình tạo dựng và hoàn thiện các giả thuyết của mình. Từ đó có thể thu được kết quả mà bạn muốn từ quá trình này.
Mục đích của việc đưa ra giả thuyết chính là sắp xếp và phân loại dữ liệu
IV. Xem xét dữ liệu một cách kỹ lưỡng
Mặc dù đã cân nhắc và đưa ra giả thuyết, nhưng đừng vội vàng thử nghiệm những giả thuyết đó. Trước tiên, hãy xem xét xem liệu những dữ liệu của bạn có thích hợp với công việc đó không.
3 câu hỏi kiểm tra dưới đây sẽ giúp bạn có cái nhìn tổng quan về những câu hỏi mà chúng tôi thường đưa ra trước khi bắt tay vào phân tích dữ liệu.

1. Câu hỏi 1: Dữ liệu này có mang tính đại diện hay không?
Mục đích:
Dữ liệu phải phản ánh đúng thực tế. Bạn có thể áp dụng một trong hai cách sau:
- Toàn bộ dữ liệu
- Những mẫu dữ liệu ngẫu nhiên.
Nếu dữ liệu của bạn không bao gồm toàn bộ dữ liệu hoặc một số mẫu dữ liệu được thống kê ngẫu nhiên, thì nó sẽ không mang tính đại diện. Điều này có nghĩa bạn sẽ không thể rút ra những kết luận có giá trị từ dữ liệu này. Dĩ nhiên, nó vẫn có thể giúp ích trong việc hiểu thêm về vấn đề mà bạn đang đối mặt. Nhưng bạn nên cẩn thận hơn.
Ví dụ:
Bạn có dữ liệu về các giao dịch của khách hàng với công ty. Bạn có thể nghĩ rằng đó là toàn bộ dữ liệu. Nhưng nếu bạn bỏ sót các giao dịch tiền mặt, dữ liệu sẽ không mang tính đại diện. Đôi khi, việc thu thập và xử lý dữ liệu toàn diện quá khó khăn. Thậm chí không thực tế và rất tốn kém. Giả sử bạn muốn hiểu mức độ hài lòng của nhân viên, bạn có thể hỏi từng người hoặc chọn ngẫu nhiên một số nhân viên. Điều quan trọng là dữ liệu ngẫu nhiên này phải phản ánh gần đúng toàn bộ dữ liệu. Tức là phản ánh đúng số lượng nhân viên nam và nữ, đại diện cho các nhóm tuổi và được thu thập từ mọi phòng ban.
2. Câu hỏi 2: Nguồn gốc của dữ liệu này từ đâu? Và dữ liệu đó được thu thập như thế nào?
Mục đích:
Những dấu hiệu cho thấy dữ liệu này có thể bị sai lệch hoặc thiếu tính đại diện:
- Có bất kỳ nhóm nào thường xuyên trả lời hơn các nhóm khác không?
- Mọi người có xu hướng trả lời câu hỏi theo cách mà những người xung quanh mong muốn không?
- Nếu người thực hiện khảo sát quan tâm quá nhiều đến mục đích và lợi ích của riêng họ, chúng ta nên nghi ngờ những dữ liệu đến từ người này.
Ví dụ:
Tiếp tục với ví dụ về cuộc khảo sát nhân viên ở trên. Nếu bạn gửi bảng khảo sát tới tất cả các nhân viên về mức độ hài lòng của họ, bạn nên đảm bảo rằng kết quả mà bạn thu được đều mang tính đại diện.
- Ai là người đã thực hiện khảo sát? Những người hài lòng, những người không hài lòng, và những người quan tâm tới kết quả của cuộc khảo sát thường sẽ xuất hiện khá rõ ràng hoặc không rõ ràng.
- Thứ hai, nếu hỏi mọi người rằng họ đã làm gì thay vì quan sát những gì họ đã làm, bạn nên cẩn thận. Với tư cách là nhà kinh tế học hành vi, chăm nom sống của Julia chia sẻ rằng “Ai rồi cũng sẽ giống như nhau dù không có ý xấu.” Mọi người có xu hướng phóng đại những hành vi tích cực của bản thân và che giấu những hành vi kém tích cực (đây được gọi là thiên kiến tự đề cao). Mỗi khi dựa vào một dữ liệu mang tính cá nhân, bạn sẽ dễ rơi vào thiên kiến này.
3. Câu hỏi 3: Dữ liệu này bị thiếu những đối tượng nào?
Mục Đích
Việc biết bạn đã bỏ lỡ những đối tượng hay thông tin nào trong dữ liệu là rất quan trọng. Bạn cần chú ý đến hai điều sau:
- Bỏ sót dữ liệu một cách ngẫu nhiên: Bạn đã bỏ sót một vài thông tin. Nhưng điều đó không hề ảnh hưởng tới những biến số mà bạn quan tâm.
- Bỏ sót dữ liệu một cách có chủ đích: Bạn đã bỏ sót một vài thông tin. Và điều đó làm ảnh hưởng tới những biến số mà bạn quan tâm. Bạn đang có những thiên kiến có thể làm sai lệch kết qủa mà bạn thu được từ dữ liệu.
Ví dụ:
Sau đây là ví dụ về 2 loại bỏ sót dữ liệu:
- Bỏ sót dữ liệu một cách ngẫu nhiên: Ví dụ, vào tháng Năm, máy bán hàng trong một cửa hàng của bạn đã không quản lý chính xác những giao dịch đã được thực hiện trong một ngày nào đó. Bạn chỉ có dữ liệu giao dịch hàng hoá chung của 364 ngày. Trừ những ngày lễ đặcq biệt (ví dụ như Black Friday), thì thiếu đi thông tin của ngày nào đó trong năm sẽ không làm thay đổi kết quả phân tích doanh thu của cửa hàng. Bạn hoàn toàn có thể lấy dữ liệu của ngày nào đó từ năm trước để bù đắp cho phần dữ liệu còn thiếu.
- Bỏ sót dữ liệu một cách có chủ đích: Ví dụ, trong dữ liệu bán hàng, có một số tiểu bang không cho phép bán hàng trực tuyến. Bạn chỉ có thể bán hàng trực tiếp tại các cửa hàng. Trong trường hợp này, bạn cần tìm cách để thu thập dữ liệu còn thiếu trước khi tiến hành phân tích dữ liệu. Hoặc bạn cũng có thể sử dụng dữ liệu mà bạn đang có để đánh giá nhân viên bán hàng. Chứ không dùng nó để đánh giá chất lượng của kênh bán hàng trực tuyến.
V. Phân loại dữ liệu thành từng nhóm
1. Sử dụng giá trị trung bình làm điểm tham chiếu
Vậy là bạn đã xem qua bảng phân tích ở trên. Và cảm thấy thoải mái hơn với dữ liệu mà mình đang có. Dữ liệu này có tính đại diện, tương đối khách quan và phù hợp với mục đích của bạn. Bây giờ, hãy bắt đầu sử dụng nó một cách hiệu quả.
Bộ não của chúng ta yêu thích thứ mà các nhà kinh tế học gọi là “điểm tham chiếu“. Đó là những mẫu dữ liệu mà chúng ta có thể dựa vào và bắt đầu sắp xếp lại suy nghĩ của bản thân. Và chúng ta thường chọn giá trị trung bình làm điểm tham chiếu. Trong toán học, để tính trung bình, ta phải chia tổng của các giá trị trong tập hợp cho số phần tử trong tập hợp. Theo đó, giá trị trung bình khá hữu ích vì nó cho phép chúng ta biết được điều gì là đúng và điều gì là sai.
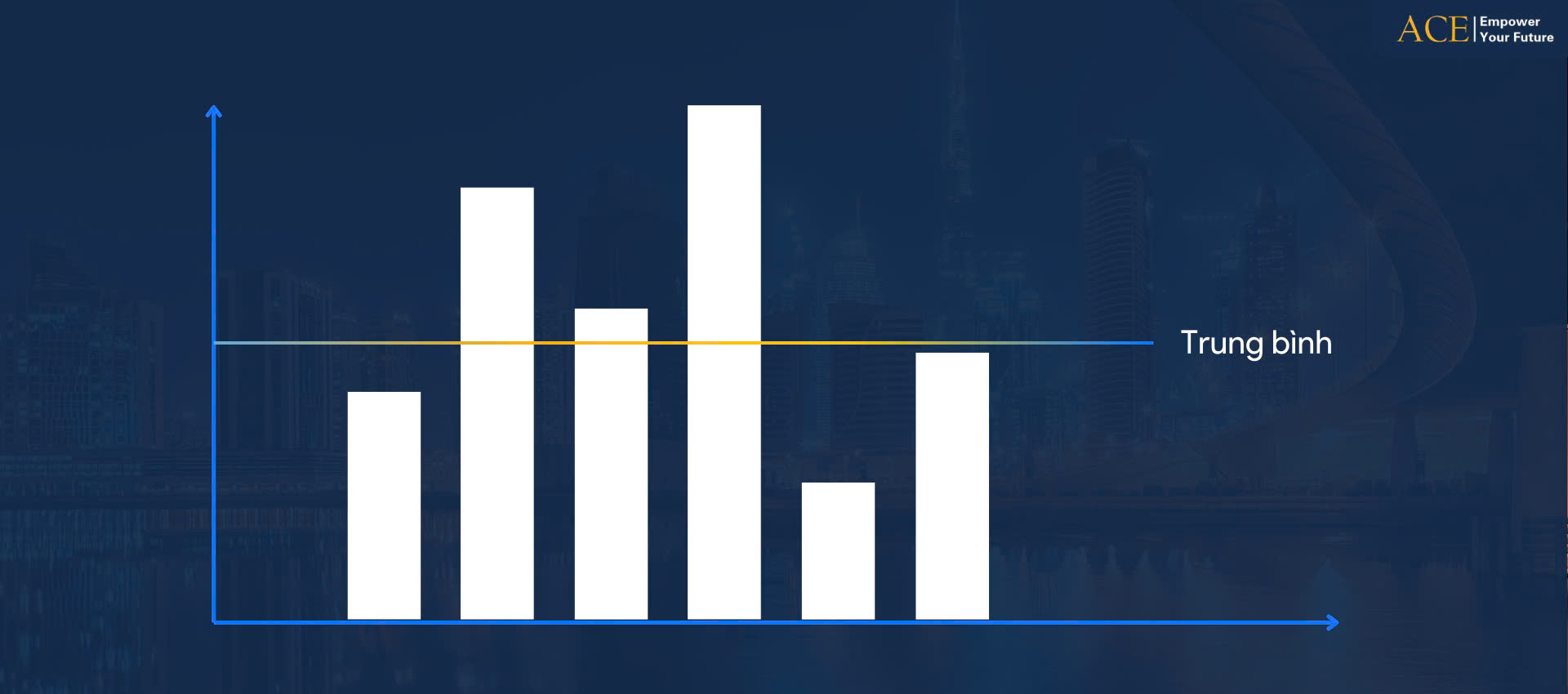
Nhưng ở một góc độ khác, giá trị trung bình lại hầu như chẳng giúp ích được gì. Và quan điểm mà các giáo viên, nhà giáo dục, chính trị gia và nhà phân tích thường đưa ra về hiệu suất trung bình đôi khi có thể khiến mọi người hiểu lầm, thậm chí còn khá nguy hiểm. Mặt khác, giá trị trung bình cũng có thể là động lực cực kỳ lớn để mọi người phấn đấu. Vì chúng ta có xu hướng thích so sánh bản thân với mức trung bình, cố gắng vượt qua nó.
2. Phân tích dữ liệu qua biểu đồ và thống kê mô tả
Quan sát và phân phối dữ liệu qua biểu đồ
Để bắt đầu, hãy cùng xem ví dụ về giáo viên sinh học và 30 học sinh trong lớphọc. Giáo viên này thường đưa ra những bài kiểm tra viết định kỳ để đánh giá mức độ hiểu của học sinh về những kiến thức trong suốt khóa học. Tất nhiên, có những học sinh đạt thành tích cao hơn so với những bạn khác trong lớp. Và biểu đồ dưới đây sẽ thể hiện số lượng về thành tích của chúng trong kỳ thi vừa qua:
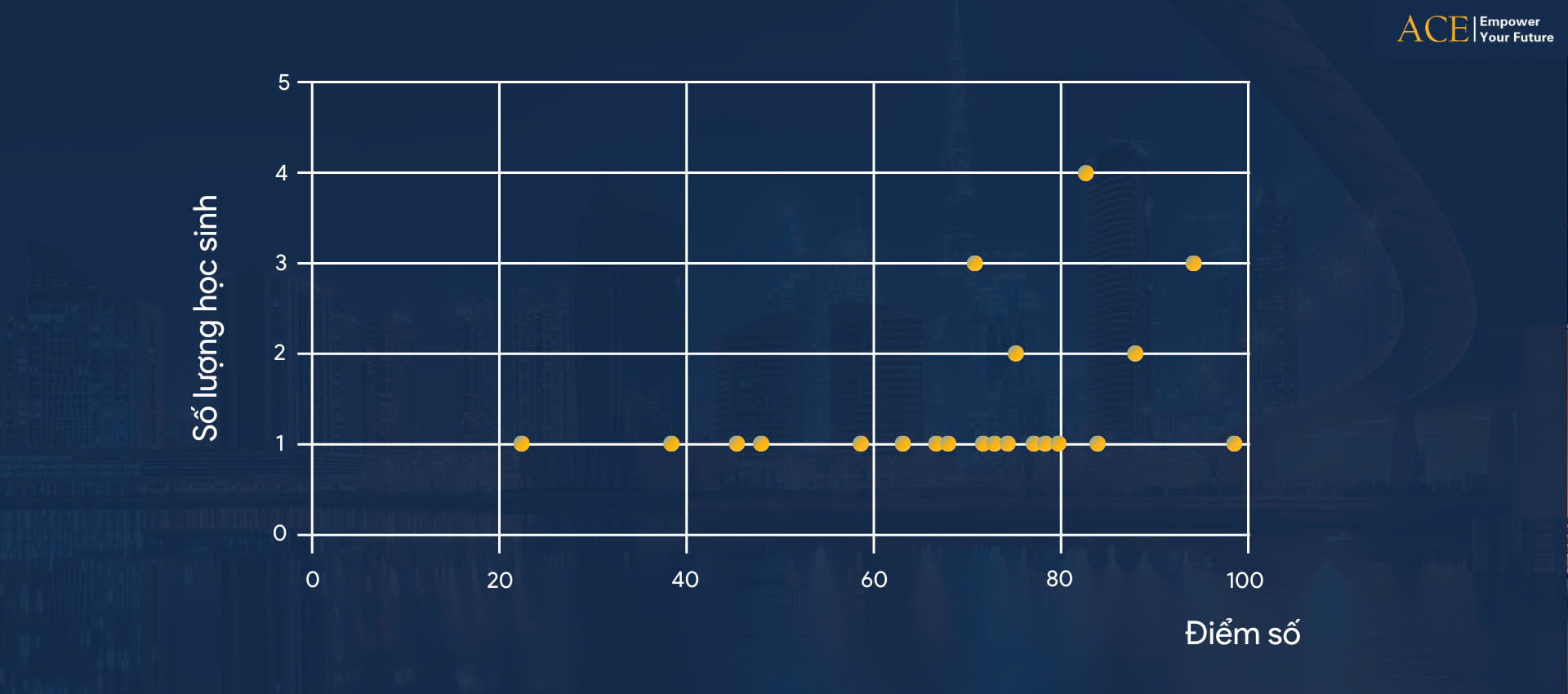
Hãy quan sát cách dữ liệu được phân phối như thế nào trong biểu đồ trên đây. Ta có một vài học sinh có kết quả kiểm tra thấp hơn 50 điểm. Phần lớn học sinh có số điểm dao động trong khoảng từ 60 cho tới 80. Và kha khá số học sinh đạt trên 80 điểm. Để quan sát, đánh giá dữ liệu hiệu quả, điều đầu tiên nên làm là đưa dữ liệu đó vào một biểu đồ tần suất Histogram. Dạng biểu đồ này có thể giúp bạn biểu thị dữ liệu một cách rõ ràng, chuẩn xác nhất.
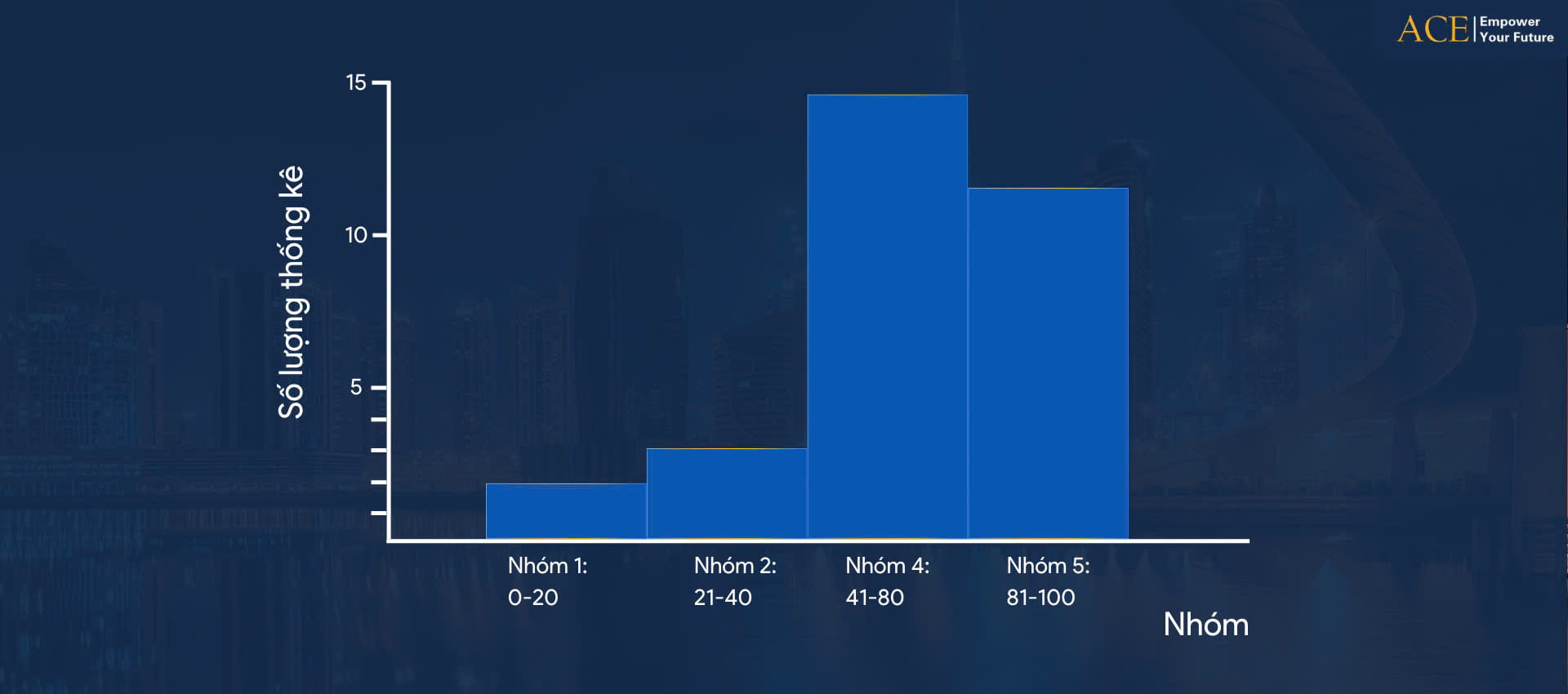
Đánh giá dữ liệu qua biểu đồ tần suất
Một khi có được biểu đồ này, có thể ngay lập tức kiểm tra và đánh giá dữ liệu. Hãy xem biểu đồ bên dưới để biết sơ lược cách phân phối của dữ liệu. Trong lớp, có những học sinh đạt được kết quả xuất sắc bài kiểm tra. Nhưng cũng có học sinh làm bài không tốt. Hãy hình dung nếu bạn áp dụng cách làm này đánh giá nhân viên bán hàng dựa trên doanh thu. Hoặc đội ngũ hỗ trợ IT dựa trên số lượng yêu cầu đã hoàn thành. Bạn sẽ nhận thấy ngay hiệu quả của biểu đồ tần suất trong việc định hình ấn tượng dữ liệu. Chúng ta có thể thấy kha khá học sinh đạt kết quả xuất sắc. Rất nhiều học sinh đạt kết quả tốt. Và một số học sinh đạt kết quả kém trong bài kiểm tra này.
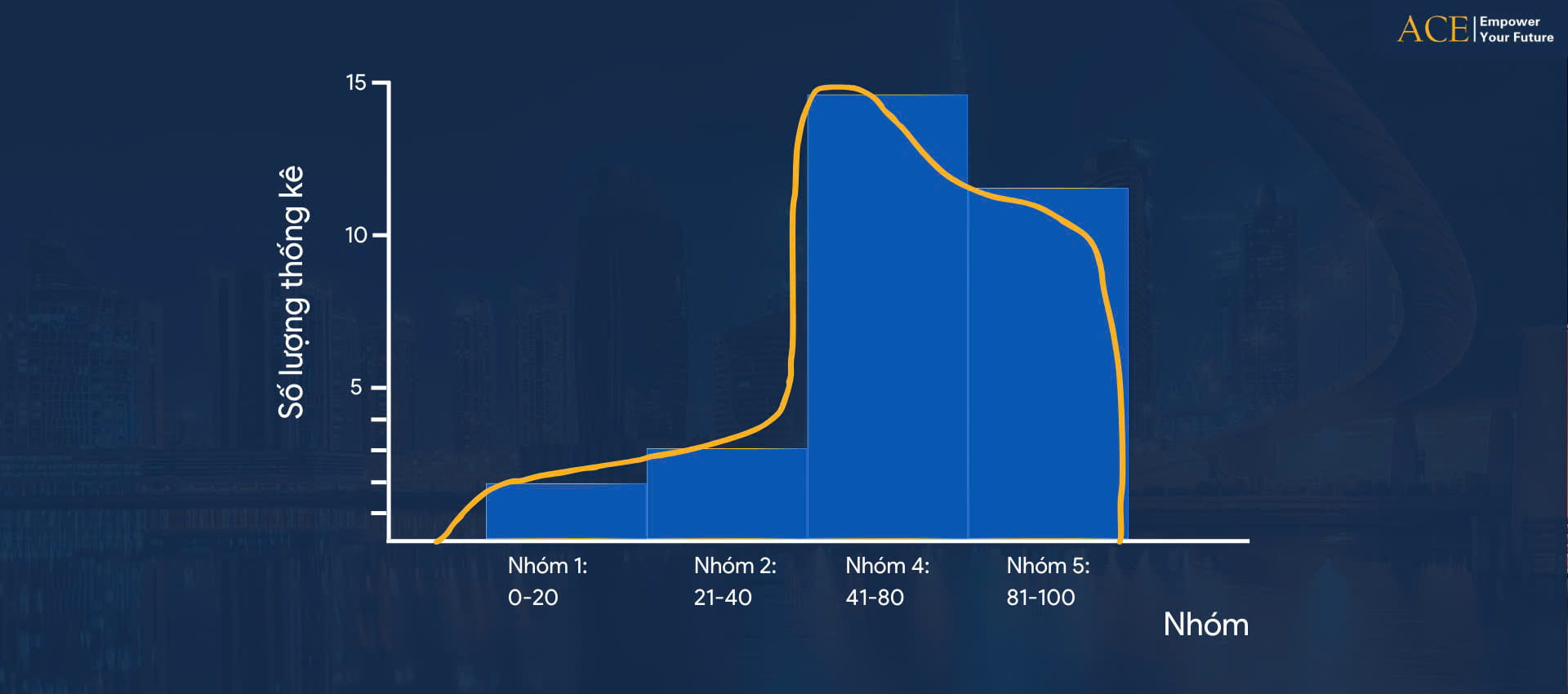
Phân tích dữ liệu và sử dụng thống kê mô tả
Sau khi xem biểu đồ, có thể thấy trong trường hợp này, điểm số trung bình không còn hữu dụng. Nhưng cũng sẽ có những số điểm khác khá hữu ích mà bạn nên biết. Bạn muốn biết phạm vi điểm số bằng cách nhìn vào số điểm thấp nhất và số điểm cao nhất. Sau khi vẽ biểu đồ, hãy ngay lập tức áp dụng phương pháp thống kê mô tả (Descriptive Statistics). Để dễ dàng tìm ra câu chuyện sau những con số đó. Chúng tôi cũng sẽ thực hiện chính xác điều đó ở trang kế tiếp. Mục đích của việc này chính là giúp bạn hiểu được ý nghĩa của dữ liệu. Nhưng việc đưa ra kết luận ở bước này không thực sự cần thiết.
Mục đích của việc thống kê mô tả chính là giúp bạn hiểu được ý nghĩa của dữ liệu, nhưng việc đưa ra kết luận ở bước này không thực sự cần thiết.
Ví dụ, khi quan sát biểu đồ trên, chúng ta không biết được độ khó của bài kiểm tra. Liệu những học sinh có kết quả thấp nhất có bị rối trí. Bị bệnh hay bị phân tâm khi làm bài hay không. Một khi bạn đã có được biểu đồ tần suất trong tay, bước tiếp theo bạn nên làm chính là “tóm tắt năm số.”
VI. Descriptive Statistics – Các sử dụng phương pháp thống kê mô tả?
1. Tóm tắt năm số và biểu đồ hình hộp
Tóm tắt năm số là công cụ đơn giản giúp khám phá những dữ liệu bạn đang có một cách sâu sắc hơn. Đối với dữ liệu về điểm số của học sinh, chúng ta có thể sử dụng biểu đồ sau:

Biểu đồ này còn được biết đến với cái tên biểu đồ hình hộp Box Plot. Nó có khả năng trực quan hóa dữ liệu. Trong biểu đồ hình hộp, có năm con số được hiển thị:
- Trung vị, hay con số nằm ở chính giữa trục hoành. Sẽ rất hữu ích khi bạn xác định trung vị cũng như số điểm trung bình. Vì nó thường ít nhạy cảm hơn với những giá trị khác. Ví dụ như số điểm quá cao hoặc quá thấp).

- Giá trị quan sát nhỏ nhất trong tập hợp dữ liệu (trong trường hợp này là bạn học sinh thiếu may mắn với số điểm 20).

- Giá trị quan sát lớn nhất trong tập hợp dữ liệu (trong trường hợp này là bạn học sinh thông minh với số điểm 99).
2. Tứ phân vị và áp dụng biểu đồ
Bên cạnh đó, còn có hai giá trị tứ phân vị:
- Tứ phân vị thứ nhất (Q1) là số điểm 67
- Tứ phân vị thứ ba (Q3) là số điểm 85.

Không mất quá nhiều thời gian để thực hiện việc phân tích dữ liệu như trên. Đối với một tập hợp dữ liệu nhỏ, bạn hoàn toàn có thể phác thảo bằng tay như chúng tôi. Đối với một tập hợp dữ liệu lớn, các phần mềm phân tích dữ liệu (như Excel, SPSS, Stata, R) có thể cho phép bạn xử lý dữ liệu gần như ngay lập tức. Nếu là quản lý của một nhóm chuyên viên phân tích dữ liệu, bạn có thể yêu cầu nhân viên của mình báo cáo sơ lược bằng phương pháp này trước khi đi vào phân tích sâu hơn. Như vậy, bạn sẽ có thể kiểm tra thực tế những dữ liệu mà mình đang xử lý.
3. Lợi ích của biểu đồ hình hộp trong quản lý
Ba dạng biểu đồ trên (biểu đồ phân tán, biểu đồ tần suất và biểu đồ hình hộp) có thể trở thành công cụ đắc lực giúp bạn hiểu hơn về những dữ liệu mà mình đang có. Hãy tưởng tượng bạn là người quản lý của trung tâm chăm sóc khách hàng. Dữ liệu ở trên thể hiện số phút nhàn rỗi trung bình giữa các cuộc gọi của các nhân viên. Giờ đây, rất dễ để bạn xác định nhân viên nào dẫn đầu và nhân viên nào trì trệ. Cũng như thấy được sự khác biệt về hiệu suất giữa các nhân viên.
Trong ví dụ trên, nhờ biểu đồ hình hộp, giáo viên có thể phân tích được dữ liệu đang có. Thay vì một tập hợp gồm 30 học sinh, bây giờ giao viên có bốn nhóm học sinh. Và mỗi nhóm cần có phương pháp khác nhau để cải thiện điểm số của mình.
VII. Có bao nhiêu dạng phân phối dữ liệu – Data Distribution?
Khi bạn đã xem qua những biểu đồ ví dụ, chúng tôi muốn giới thiệu đến bạn một số dạng phân phối dữ liệu phổ biến. Giúp bạn biết được trong trường hợp nào thì nên sử dụng chúng. Qua đó, bạn có thể đưa ra kết luận về những gì mình quan sát được. Quan trọng hơn, việc biết về các dạng phân phối dữ liệu phổ biến sẽ giúp bạn dự đoán được những dữ liệu mà bạn chưa quan sát. Hiểu rõ phương pháp phân phối dữ liệu chính là cách để bạn chuyển từ những quan sát đơn lẻ sang việc xác định khuôn mẫu của dữ liệu.
1. Phân phối chuẩn – Normal Distribution
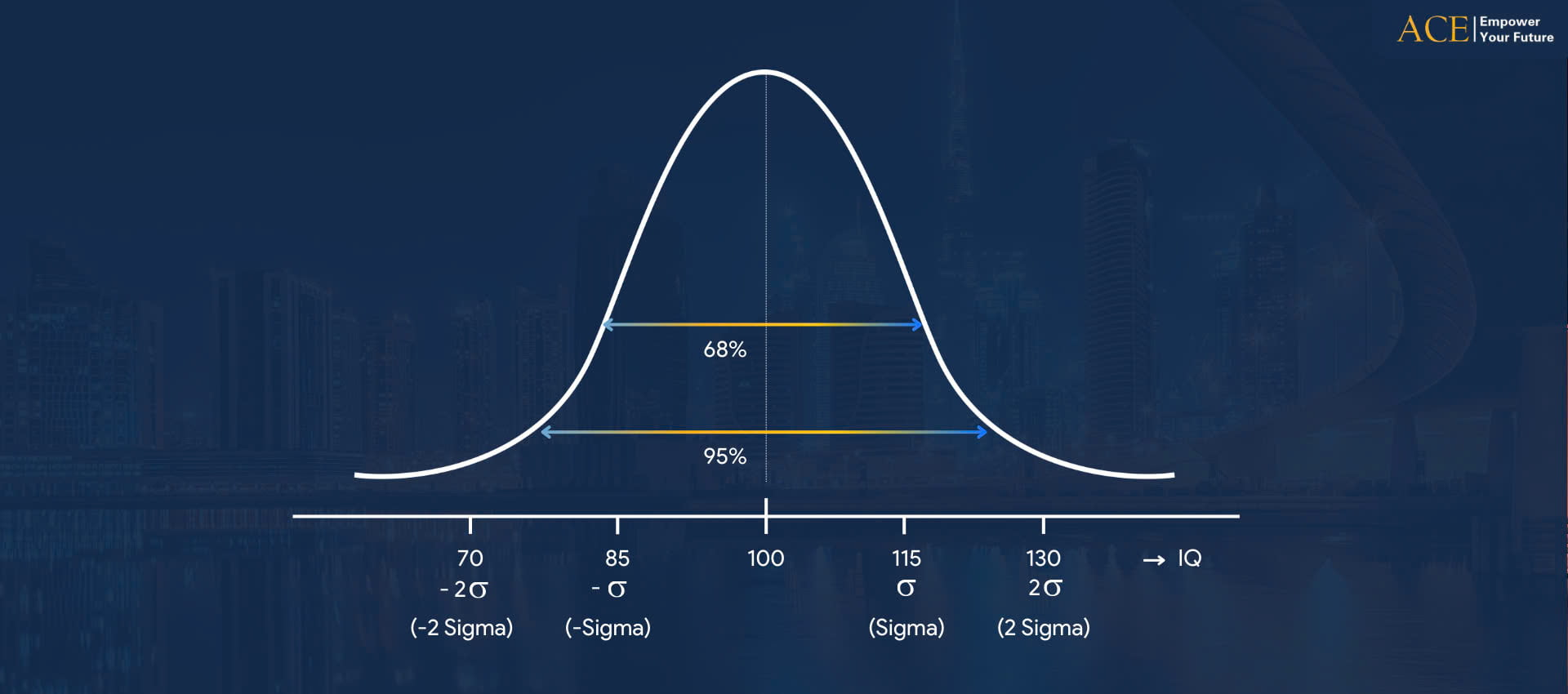
Phân phối chuẩn, hay còn gọi là đường cong hình chuông hoặc phân phối Gaussian (theo tên nhà toán học và vật lí Carl Friedrich Gauss), là dạng phân phối dữ liệu phổ biến nhất trong lịch sử. Ví dụ, phân phối chiều cao hoặc chỉ số IQ của con người thường có dạng hình chuông. Chỉ số IQ trung bình của con người được chuẩn hóa ở mức 100. Dựa trên số liệu này, bạn có thể thấy rằng 68% dân số có IQ từ 85 đến 115, và 95% dân số nằm ở mức từ 70 đến 130. Hay nói cách khác, để tìm được một người có chỉ số IQ trên 130 hay một người có chỉ số IQ thấp hơn 70 thực sự là một thử thách khó khăn.
2. Phân phối Pareto – Pareto Distribution

Có thể bạn đã từng nghe nói về nguyên tắc 80:20. Đây là ý tưởng cho rằng 80% doanh thu của công ty đến từ 20% nhân viên bán hàng, hoặc 80% trường hợp khiếu nại bắt nguồn từ 20% khách hàng. Hiện tượng phổ biến này được phản ánh trong nguyên tắc Pareto (The Pareto Principle). Khi nhìn thấy dạng phân phối như thế này, bạn sẽ rút ra được rằng một lượng nhỏ yếu tố đầu vào có khả năng tạo ra một lượng lớn kết quả đầu ra.
Bạn có thể nhìn thấy dạng phân phối này ở đâu? Nhiều cộng đồng (đặc biệt là cộng đồng trực tuyến như Wikipedia và YouTube) được thúc đẩy bởi siêu người dùng (super-users). Thuật ngữ siêu người dùng ám chỉ những cá nhân dành phần lớn thời gian và năng lượng của bản thân trên một nền tảng nào đó. Siêu người dùng của công ty bạn là những giá trị ngoại lai nằm ngoài (hoặc nằm rất xa) hai độ lệch chuẩn mà chúng tôi đã đề cập ở trên. Tuy nhiên, tác động mà họ tạo ra có thể không cân xứng.
Chẳng hạn, trong năm 2015, một trang blog nổi tiếng có tên Priceonomics đã báo cáo rằng Wikipedia có những giá trị ngoại lai khá lớn. Trong số 26 triệu thành viên đăng ký của Wikipedia, có khoảng 125.000 người dùng (dưới 0.5%) có những đóng góp tích cực. Và trong số 125.000 người này, chỉ có 12.000 người đã thực hiện việc chỉnh sửa hơn 50 lần trong vòng 6 tháng.
Khi suy nghĩ về những khách hàng trung bình, bạn cũng nên tự hỏi rằng ai là siêu người dùng của bạn và họ đã có đóng góp gì cho bạn?Bạn đã phục vụ hay đánh giá cao những khách hàng ngoại lệ này hay chưa?Liệu quyết định mà bạn sắp đưa ra có đem lại lợi ích cho họ hay không?
3. Phân phối Poisson – Poisson Distribution

Phân phối Poisson được sử dụng để ước tính xác suất xảy ra của một số sự kiện trong một khoảng thời gian hoặc không gian cố định. Với điều kiện các sự kiện xảy ra là ngẫu nhiên và độc lập.
Bất cứ khi nào muốn ước tính số lượng sự kiện trên một đơn vị thời gian, khu vực hoặc khối lượng, bạn có thể sử dụng phân phối Poisson. Một ví dụ điển hình cho dạng phân phối này chính là danh sách những binh lính Phổ vô tình thiệt mạng do bị ngựa đá từ năm 1875 đến năm 1894. Bạn cũng có thể sử dụng dạng phân phối này cho lượt đến và đi của khách hàng ở một cửa hàng bán lẻ theo từng giờ. Số lượng khách hàng phàn nàn về một vấn đề nào đó theo từng tháng. Hay số lượng máy bay gặp tai nạn theo mỗi triệu giờ bay.
4. Phân phối đồng nhất – Uniform probability distribution
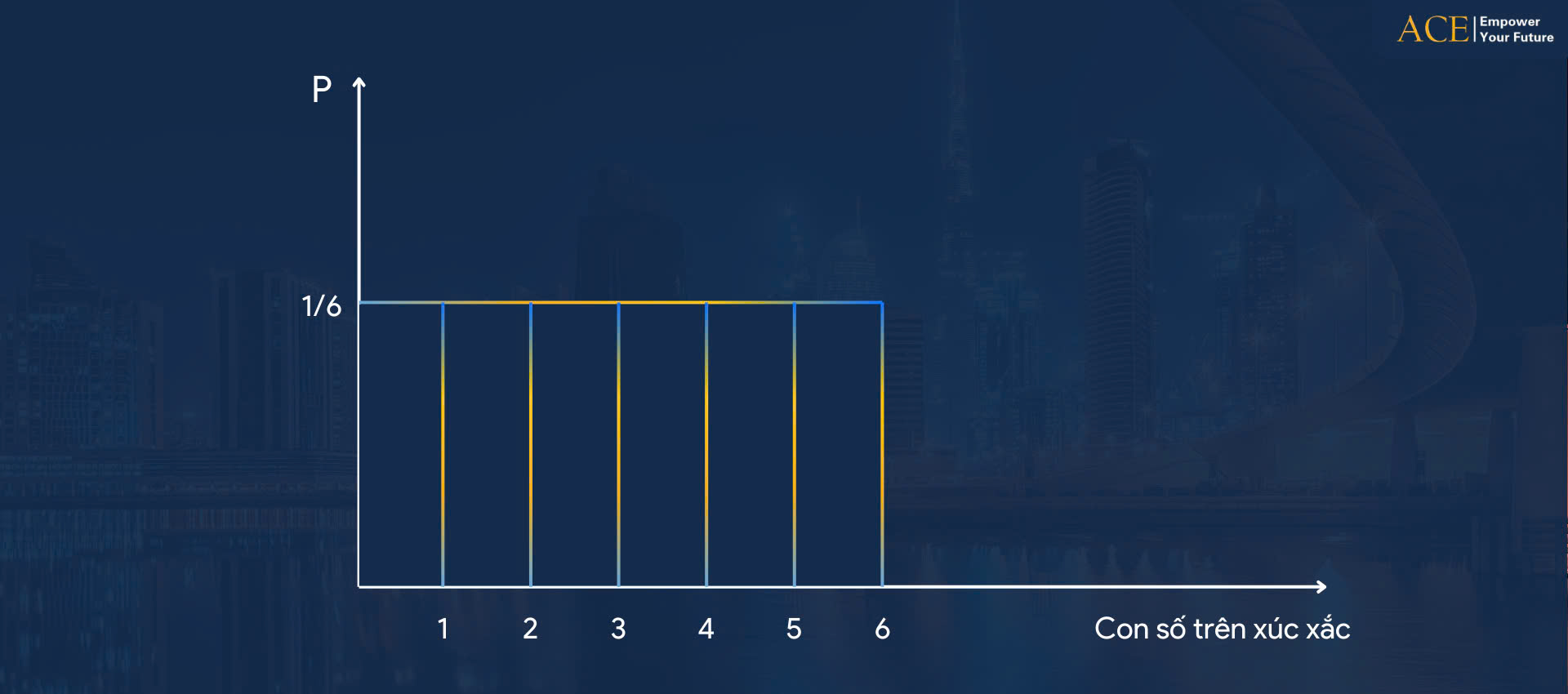
Phân phối đồng nhất (hay còn gọi là phân phối hình chữ nhật) là dạng phân phối đơn giản nhất. Một ví dụ điển hình cho dạng phân phối này là số seri trên một tờ đô la được lựa chọn ngẫu nhiên. Hay con số mà bạn nhận được khi gieo xúc xắc hoặc quay roulette.
Tóm tắt 5 loại phân phối trong thống kê mô tả
| Loại phân phối | Đặc điểm chính | Ví dụ thực tiễn | Ý nghĩa phân tích |
|---|---|---|---|
| Phân phối chuẩn (Normal Distribution) | Có dạng hình chuông, tập trung nhiều giá trị quanh trung bình. | Chiều cao, IQ, điểm thi chuẩn hóa | Giúp hiểu sự phân bố tự nhiên, phát hiện ngoại lệ dễ dàng. Sử dụng nhiều trong kiểm định giả thuyết. |
| Phân phối Pareto (Pareto Distribution) | Áp dụng nguyên tắc 80/20 – phần nhỏ tạo ra phần lớn kết quả. | 20% khách hàng tạo ra 80% doanh thu, 0.5% người dùng Wikipedia tạo phần lớn nội dung | Xác định nhóm “siêu người dùng” hoặc “điểm tạo ảnh hưởng mạnh” để tối ưu hoá chiến lược. |
| Phân phối Poisson (Poisson Distribution) | Ước tính số lần sự kiện xảy ra trong đơn vị thời gian/khoảng không gian. | Lượt khách vào cửa hàng theo giờ. Số khiếu nại mỗi tháng, tai nạn máy bay theo giờ bay | Giúp dự đoán tần suất sự kiện hiếm. Hỗ trợ lập kế hoạch và tối ưu nguồn lực. |
| Phân phối đồng nhất (Uniform Distribution) | Xác suất các giá trị xảy ra bằng nhau trong một khoảng nhất định. | Gieo xúc xắc, quay roulette, chọn số seri đô la ngẫu nhiên | Dùng khi không có lý do để thiên vị một kết quả nào. Phù hợp cho mô phỏng và trò chơi xác suất. |
| Phân phối dữ liệu tổng quát | Khái niệm bao trùm, đề cập đến cách dữ liệu phân tán trong tập dữ liệu. | Tất cả các biểu đồ histogram, density plot, boxplot… | Là bước đầu tiên để chọn phương pháp phân tích. Mô hình hoá phù hợp với đặc điểm dữ liệu cụ thể. |
VIII. Kết luận
Dữ liệu mà bạn sử dụng để bắt đầu quá trình phân tích sẽ quyết định mức độ hữu ích của những kết quả bạn thu được. Bạn phải đảm bảo dữ liệu đó là dữ liệu có chất lượng. Từ đó đưa ra những giả thuyết để hiểu rõ thông tin mà bạn đang có. Hãy luôn tìm cách vượt qua mức trung bình và quan sát dữ liệu của bạn một cách toàn diện (bằng cách xem xét thống kê mô tả và hình thành quan điểm về những dạng phân phối dữ liệu phù hợp). Đó là cách để bạn có được cái nhìn sâu sắc về vấn đề mà bản thân đang đối mặt.
Bài viết đã cùng bạn hiểu hơn về thống kê mô tả và những vấn đề quan trọng của nó. Sự hiểu biết sâu sắc về dữ liệu không chỉ cải thiện các quyết định hiện tại. Đồng thời, mở ra cánh cửa cho những cơ hội mới. Giúp doanh nghiệp của bạn luôn đi đầu và thích ứng với thay đổi. Bạn có sẵn sàng biến dữ liệu thành một trợ thủ đắc lực cho mình? Hãy khám phá khóa học “Data Analysis for Business Professional” tại ACE Academy. Tham gia cùng chúng tôi để không chỉ học cách phân tích dữ liệu. Mà còn để khám phá điều thú vị dữ liệu mang lại! Đăng ký ngay hôm nay để không chỉ theo kịp xu hướng mà còn dẫn đầu trong cuộc đua tiếp thị thông minh.

Câu hỏi thường gặp về thống kê mô tả (Descriptive statistics)
Thống kê mô tả là gì?
Khi nào nên dùng phương pháp thống kê mô tả?
Các loại phân phối phổ biến trong thống kê mô tả là gì?
Thống kê mô tả khác gì với thống kê suy luận?
Thống kê mô tả được áp dụng trong công cụ nào?













Phân tích hồi quy là gì? Hướng dẫn ứng dụng Hồi Quy Tuyến Tính
[…] Nếu bạn muốn tìm hiểu thêm về các phương pháp thống kê khác, tìm hiểu thêm về Phương pháp thống kê mô tả Descriptive Statistics tại đây […]