Outlier là gì? Phương phap xác định và loại bỏ dữ liệu ngoại lai (outlier) hiệu quả
Outlier (dữ liệu ngoại lai) là những điểm dữ liệu khác biệt bất thường so với phần lớn tập dữ liệu còn lại, có thể gây sai lệch kết quả phân tích nếu không được xử lý đúng cách. Việc xác định và loại bỏ outlier giúp nâng cao độ chính xác của mô hình, hạn chế rủi ro trong ra quyết định kinh doanh.
Trong bài viết này, ACE Academy sẽ giúp bạn hiểu rõ outlier là gì, vì sao cần xử lý outlier, cùng các phương pháp xác định và loại bỏ outlier hiệu quả trong phân tích dữ liệu.
I. Outlier (dữ liệu ngoại lai) là gì?
Để hiểu rõ hơn về Outlier là gì, hãy tưởng tượng bạn đang phân tích một tập dữ liệu có tính đồng nhất. Trong đó, có một vài điểm dữ liệu có giá trị khác biệt hoàn toàn so với phần còn lại. Đó chính là Outlier.
Outlier (dữ liệu ngoại lai) là những giá trị đơn lẻ hoặc các điểm dữ liệu không tuân theo xu hướng hoặc mô hình chung của tập dữ liệu. Nói cách khác, Outlier là các điểm bất thường. Nằm lệch khỏi phạm vi phân phối của các giá trị thông thường trong tập dữ liệu.
Giả sử bạn đang thực hiện phân tích thu nhập của người dân trong một thành phố:
- Hầu hết người dân có mức thu nhập dao động từ 20.000 đến 100.000 USD/năm.
- Tuy nhiên, có một cá nhân có thu nhập lên tới 1 triệu USD/năm. Đây là một giá trị vượt xa so với phân phối chung của tập dữ liệu
Trong trường hợp này, người có thu nhập 1 triệu USD/năm được coi là một Outlier. Vì giá trị của họ khác biệt rõ rệt so với phần còn lại của tập dữ liệu.
II. Tại sao cần xác định và loại bỏ Outlier?
Việc xác định và loại bỏ Outlier là cần thiết vì những lý do sau:
- Cải thiện độ chính xác của mô hình: Các giá trị ngoại lai có thể làm méo mó các mô hình phân tích. Dẫn đến kết quả sai lệch.
- Loại bỏ sai sót trong dữ liệu: Nếu Outlier xuất hiện do lỗi nhập liệu hoặc lỗi thu thập, loại bỏ chúng sẽ giúp dữ liệu chính xác hơn.
- Tăng hiệu quả phân tích: Khi dữ liệu được làm sạch, các mô hình thống kê và thuật toán học máy (Machine Learning) sẽ hoạt động tốt hơn. Từ đó đưa ra dự đoán chính xác hơn.
III. Nguyên nhân dẫn đến Outlier (Dữ liệu ngoại lai) là gì?

Sự xuất hiện của Outlier trong tập dữ liệu có thể do nhiều nguyên nhân khác nhau. Vậy những nguyên nhân xuất hiện Outlier là gì?
1. Lỗi trong quá trình thu thập dữ liệu:
Lỗi nhập liệu, lỗi cảm biến hoặc lỗi trong quy trình xử lý dữ liệu có thể tạo ra các giá trị bất thường.
2. Biến động tự nhiên trong dữ liệu:
Trong một số trường hợp, dữ liệu có thể xuất hiện các giá trị bất thường một cách tự nhiên do tính chất ngẫu nhiên của dữ liệu hoặc biến động theo thời gian.
3. Sự thay đổi về điều kiện bên ngoài:
Những thay đổi trong thị trường, môi trường kinh doanh hoặc các yếu tố kinh tế có thể dẫn đến sự xuất hiện của các giá trị bất thường.
- Ví dụ: Trong thời gian đại dịch COVID-19, doanh số bán khẩu trang và nước rửa tay khô tăng vọt gấp 5 lần so với thời điểm bình thường. Đây là một sự thay đổi bất thường về dữ liệu do ảnh hưởng từ điều kiện bên ngoài là COVID-19.
Việc xác định đúng nguyên nhân dẫn đến Outlier là rất quan trọng để đưa ra quyết định xử lý phù hợp.
- Nếu Outlier là kết quả của lỗi thu thập hoặc nhập liệu, bạn có thể loại bỏ chúng.
- Tuy nhiên, nếu Outlier là do sự thay đổi về điều kiện bên ngoài hoặc biến động tự nhiên, việc giữ lại các giá trị đó có thể cung cấp thông tin giá trị cho các mô hình phân tích.
IV. Khi nào chúng ta cần loại bỏ Outlier?
Trong quá trình phân tích dữ liệu, việc xác định Outlier là gì và loại bỏ Outlier là rất quan trọng để đảm bảo kết quả phân tích chính xác và đáng tin cậy. Dưới đây là những trường hợp mà việc loại bỏ Outlier là cần thiết:
1. Khi Outlier là kết quả của lỗi trong quá trình thu thập hoặc xử lý dữ liệu
Những giá trị ngoại lai xuất hiện do lỗi trong quá trình thu thập, nhập liệu hoặc cảm biến cần được loại bỏ để đảm bảo độ chính xác của dữ liệu.
- Ví dụ: Một cân điện tử bị hỏng ghi nhầm trọng lượng của một vật là 1000 kg thay vì 10 kg. → Rõ ràng đây là một lỗi nhập liệu. Và giá trị 1000 kg nên được loại bỏ để tránh làm méo phân phối của dữ liệu.
2. Khi Outlier làm sai lệch phân bố của dữ liệu
Outlier có thể làm méo phân bố của dữ liệu. Dẫn đến sự sai lệch trong các thống kê mô tả như:
- Giá trị trung bình (mean)
- Phương sai (variance)
- Phân vị (quartile)
Nếu Outlier làm méo các chỉ số này, chúng ta nên loại bỏ chúng để cải thiện chất lượng của dữ liệu.
- Ví dụ: Giả sử bạn có một nhóm học sinh với điểm trung bình là 7. Tuy nhiên, trong nhóm này có một học sinh đạt điểm 10 và một học sinh đạt điểm 0. → Hai giá trị này là Outlier. Và có thể làm sai lệch phân phối của dữ liệu.
3. Khi Outlier làm giảm hiệu quả của các mô hình Machine Learning
Outlier có thể làm giảm hiệu quả của các thuật toán học máy như:
- Hồi quy tuyến tính (Linear Regression)
- Phân loại logistic (Logistic Regression)
- Phân cụm k-means (K-means Clustering)
Outlier có thể khiến mô hình học máy học sai xu hướng. Hoặc đưa ra các dự đoán không chính xác.
- Ví dụ: Giả sử bạn đang phân tích chiều cao và cân nặng của một nhóm người: Đa số người có chiều cao từ 1,5 m đến 1,8 m và cân nặng từ 50 kg đến 80 kg. Tuy nhiên, có một giá trị là 2.2 m và 38 kg. Đây là một Outlier vì nó không tuân theo xu hướng chung của dữ liệu. → Giữ lại giá trị này có thể khiến mô hình học máy đưa ra các dự đoán không chính xác. Vì vậy nên loại bỏ giá trị này.
Tóm tắt các trường hợp cần loại bỏ Outlier
Outlier nên được loại bỏ trong phân tích dữ liệu khi:
- Dữ liệu bị lỗi kỹ thuật hoặc nhập sai: Giá trị phát sinh từ lỗi cảm biến, nhập nhầm hoặc sai định dạng không phản ánh thực tế.
- Outlier làm méo phân phối dữ liệu: Gây ảnh hưởng tới các chỉ số thống kê như mean, median, variance hoặc skewness.
- Outlier ảnh hưởng đến độ chính xác mô hình: Làm sai lệch kết quả dự báo trong các thuật toán học máy như hồi quy, phân loại hoặc phân cụm.
V. Những trường hợp nào không nên loại bỏ Outlier?
Mặc dù trong nhiều trường hợp, việc loại bỏ Outlier là cần thiết để cải thiện độ chính xác của dữ liệu, nhưng không phải lúc nào chúng ta cũng nên loại bỏ chúng. Dưới đây là những trường hợp mà bạn nên giữ lại Outlier:
1. Khi Outlier phản ánh thông tin quan trọng của dữ liệu
Nếu Outlier đại diện cho một xu hướng hoặc hành vi đặc biệt trong dữ liệu. Việc giữ lại giá trị này có thể giúp bạn khám phá các thông tin giá trị mới.
- Ví dụ: Doanh số bán hàng của một cửa hàng thường dao động từ 1 triệu VND đến 10 triệu VND mỗi ngày. Tuy nhiên, trong dịp Tết, doanh số đột ngột tăng lên 50 triệu VND. → Đây là một Outlier nhưng phản ánh xu hướng tiêu dùng đặc biệt trong dịp Tết, nên giữ lại để phân tích.
2. Khi Outlier đại diện cho một cơ hội kinh doanh hoặc một vấn đề tiềm ẩn
Outlier có thể cho thấy một cơ hội kinh doanh hoặc một vấn đề cần giải quyết.
- Ví dụ: Một sản phẩm mới của công ty bất ngờ đạt doanh số cao hơn bình thường trong tháng đầu tiên ra mắt. → Đây là Outlier nhưng là một dấu hiệu tích cực về tiềm năng của sản phẩm. Nên giữ lại để phân tích chiến lược kinh doanh.
Vậy khi đã biết vấn đề Oulier đại diện là gì, có nên loại bỏ Outlier hay không?
Việc quyết định có loại bỏ Outlier hay không phụ thuộc vào các yếu tố sau:
- Nguyên nhân → Outlier xuất hiện do lỗi hay là thông tin giá trị thực tế?
- Ảnh hưởng → Outlier có làm sai lệch phân phối dữ liệu hoặc giảm hiệu quả của mô hình phân tích không?
- Ý nghĩa → Outlier có đại diện cho một cơ hội hoặc xu hướng đặc biệt trong dữ liệu không?
- Nếu Outlier là kết quả của lỗi kỹ thuật hoặc ảnh hưởng tiêu cực đến mô hình: Bạn nên loại bỏ chúng.
- Nếu Outlier phản ánh thông tin giá trị hoặc xu hướng quan trọng: Bạn nên giữ lại để khám phá thêm insight từ dữ liệu.

Vậy nên việc loại bỏ outlier hay không còn phụ thuộc vào nguyên nhân, ý nghĩa và tác động của Outlier đối với dữ liệu là gì. Chúng ta cần xem xét kỹ lưỡng trước khi đưa ra quyết định loại bỏ Outlier. Để không làm mất đi các thông tin quan trọng. Hoặc làm sai lệch kết quả phân tích và mô hình hóa dữ liệu.
VI. Làm thế nào để xác định Outlier (giá trị ngoại lai)?
Khi đã hiểu rõ được Ourlier là gì, tiếp theo là 3 phương pháp phổ biến nhất để xác định Outlier trong phân tích data. Bao gồm:
- Xác định trực tiếp trong bảng hoặc trang tính
- Sử dụng biểu đồ để xác định Outlier
- Sử dụng các phương pháp thống kê để xác định Outlier

Phương pháp 1: Xác định trực tiếp trong bảng hoặc trang tính
Phương pháp đơn giản nhất để phát hiện Outlier là kiểm tra trực tiếp trong bảng hoặc trang tính của tập dữ liệu. Vậy phương pháp xác định Outlier này là gì và thực hiện thế nào?
- Bằng cách sắp xếp (sort) dữ liệu theo thứ tự tăng dần hoặc giảm dần, bạn có thể dễ dàng xác định các giá trị nằm ngoài phạm vi thông thường của dữ liệu.
- Phương pháp này phù hợp cho tập dữ liệu nhỏ hoặc trung bình. Nhưng sẽ gặp khó khăn khi áp dụng cho các tập dữ liệu lớn (hàng nghìn hoặc hàng triệu dòng).
Ví dụ: Bạn đang phân tích dữ liệu về tuổi của khách hàng như trên hình:
- Giá trị của cột “Age” cho Antony Smith là 470 tuổi. Rõ ràng đây là một giá trị bất thường. Vì giá trị thực tế có thể là 47, 70 hoặc 40 tuổi. → Giá trị 470 là một Outlier. Cần được xác định và xử lý để đảm bảo tính chính xác của dữ liệu.
- Công cụ: Sử dụng tính năng Sort (sắp xếp) trong Excel hoặc Google Sheets để phát hiện nhanh các giá trị bất thường.
Mặc dù phương pháp này không cho biết mức độ nghiêm trọng của giá trị ngoại lai – Outlier là gì, nhưng đây là cách dễ dàng và nhanh chóng khi làm việc với tập dữ liệu có kích thước nhỏ hoặc trung bình.
Tuy nhiên, khi tập dữ liệu có quy mô lớn (hàng nghìn hoặc hàng triệu bản ghi), việc xác định giá trị ngoại lai theo cách thủ công sẽ rất mất thời gian và dễ xảy ra sai sót.
Phương pháp 2: Sử dụng biểu đồ để xác định Outlier
Việc trực quan hóa dữ liệu qua biểu đồ là một trong những cách hiệu quả nhất để phát hiện Outlier trong dữ liệu. Có 3 biểu đồ thường được sử dụng để xác định giá trị ngoại lai bao gồm:
- Boxplot → Xác định giá trị nằm ngoài tứ phân vị (quartile).
- Histogram → Giá trị ngoại lai sẽ xuất hiện ở phần rìa của biểu đồ. Có tần suất xuất hiện thấp.
- Scatter Plot → Các giá trị ngoại lai sẽ xuất hiện tách biệt khỏi các điểm dữ liệu khác.
1. Sử dụng Histogram để tìm outlier ngoại lai
Outlier ngoại lai thường xuất hiện ở các khoảng giá trị cách xa phân phối trung tâm của dữ liệu.
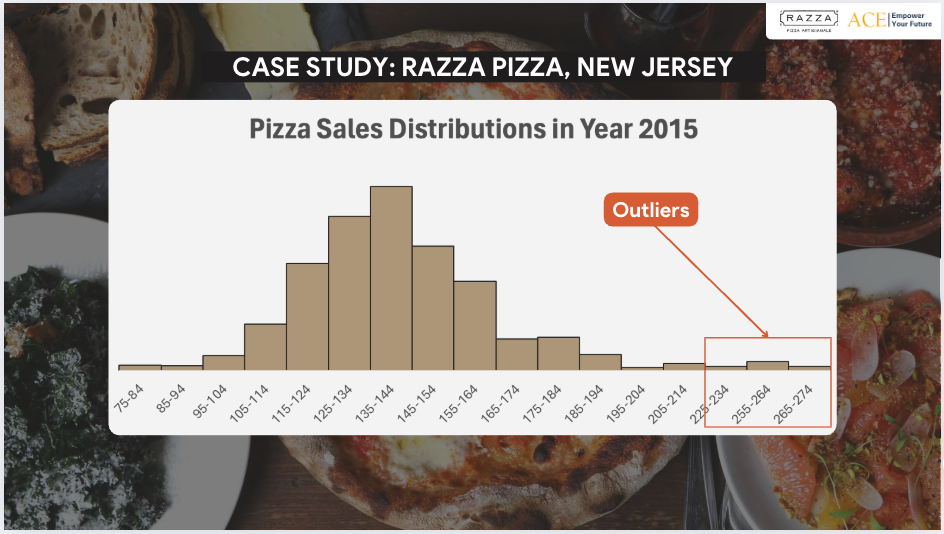
Biểu đồ Histogram dưới thể hiện phân phối doanh số bán pizza trong năm 2015 của Razza Pizza (New Jersey).
- Trục ngang (x-axis) đại diện cho khoảng giá trị của doanh số bán pizza (được chia thành các bins)
- Trục đứng (y-axis) thể hiện số lần xuất hiện (tần suất) của mỗi khoảng giá trị
- Các bins ở đầu bên phải của histogram có tần suất rất thấp so với các bins khác
Đây là các outlier ngoại lai tiềm năng → Cần phân tích sâu hơn để xác định nguyên nhân.
2. Sử dụng boxplot để tìm outlier ngoại lai
Boxplot giúp hiển thị phân phối của dữ liệu dựa trên các thông số thống kê như tứ phân vị (quartile), phạm vi liên tứ phân vị (IQR – Interquartile Range). Và các giá trị cực đại (maximum) và cực tiểu (minimum).
Vậy Outlier ngoại lai trong Boxplot là gì? Outlier ngoại lai trong Boxplot được xác định là những dấu chấm ở 2 dầu biểu đồ. Hay cũng là bằng phạm vi liên tứ phân vị (IQR) theo công thức:
Biểu đồ Boxplot trên thể hiện điểm số (Score) của bốn phương pháp giảng dạy (Teaching Method). Mục tiêu của phân tích là xác định:
- Phân phối điểm số của từng phương pháp.
- Sự khác biệt về hiệu quả giữa các phương pháp giảng dạy.
- Xác định các giá trị bất thường (Outliers) trong dữ liệu.
Ở teaching method 2 xuất hiện một outlier rõ ràng (dấu *). Cho thấy có một trường hợp đạt điểm cao hơn hẳn so với các điểm khác.
Ta phân tích chi tiết như sau:
Method 2
- Phân bố dữ liệu: Dữ liệu tập trung quanh mức trung vị. Phạm vi của hộp hẹp hơn so với Method 1.
- Whisker: Râu ngắn cho thấy dữ liệu ít biến động.
- Outlier: Xuất hiện một outlier rõ ràng (đánh dấu bằng dấu *). Cho thấy có một trường hợp đạt điểm cao hơn hẳn so với các điểm khác.
- Trung vị: Nằm gần trung tâm → Dữ liệu phân bố cân bằng.
Kết luận: Phương pháp 2 có độ ổn định cao. Nhưng xuất hiện một giá trị bất thường có thể là do sai sót hoặc yếu tố đặc biệt trong quá trình giảng dạy. Cần kiểm tra lại dữ liệu cho phương pháp này
3. Sử dụng scatter plot để tìm outlier ngoại lai
Một nghiên cứu về lịch hẹn y tế ở Brazil (Aquare.la) được thực hiện để tìm ra các yếu tố khiến người dân vắng mặt trong các cuộc hẹn y tế đã được lên lịch trước của thành phố Vitoria. Gây ra tổng thiệt hại 8 triệu đô la Mỹ mỗi năm.
Biểu đồ scatter plot dưới đây trực quan 8.000 cuộc hẹn y tế. Cho thấy các điểm bất thường (được biểu thị bằng các chấm đỏ) tách biệt hoàn toàn khỏi các giá trị còn lại.
Data analyst trong quá trình phân tích dữ liệu và trực quan biểu đồ scatter plot trên cũng đã phát hiện một trường hợp outlier ngoại lai:
Một phụ nữ 79 tuổi đã đặt lịch hẹn trước 365 ngày. Và thực sự có mặt trong cuộc hẹn với bác sỹ.
Điều này không phù hợp với các xu hướng thông thường trong dữ liệu. Vậy đây là một trường hợp ngoại lệ cần được tìm hiểu và đào sâu. Vì hành vi của người này có thể mang lại các thông tin liên quan về các biến pháp để tăng tỷ lệ có mặt của người dân.
Phương pháp 3. Sử dụng các phương pháp thống kê
Phân tích thống kê là một trong những phương pháp hiệu quả nhất để xác định và xử lý các giá trị ngoại lai outlier trong tập dữ liệu. Vậy phương pháp xác định Outlier này là gì và hỗ trợ loại bỏ outlier như thế nào?
Phương pháp phân tích thống kêcho phép so sánh các điểm dữ liệu với phân phối của tập dữ liệu để xác định những điểm bất thường. Từ đó hỗ trợ việc ra quyết định và cải thiện chất lượng phân tích dữ liệu.
1. Tính giá trị trung bình (mean) và độ lệch chuẩn (standard deviation)
Theo phân phối chuẩn, dữ liệu nằm trong khoảng ± 2 lần độ lệch chuẩn sẽ chiếm khoảng 95% của tất cả dữ liệu. Do đó, các giá trị nằm ngoài khoảng này được xem là Outlier trong phân tích thống kê.
Phương pháp này dựa trên giả định rằng tập dữ liệu tuân theo phân phối chuẩn (normal distribution). Hoặc phân phối gần chuẩn. Trong phân phối chuẩn, hầu hết các giá trị sẽ tập trung quanh giá trị trung bình (mean). Và các giá trị cách xa trung bình quá nhiều sẽ được coi là ngoại lai.
Dữ liệu ta đang xem xét là thông tin từ “Tạp chí Motor Trend US” năm 1974 về hiệu suất hoạt động (km/l) của 32 mẫu xe được các chuyên gia phân tích dữ liệu Data analyst đưa ra. Dưới đây là biểu đồ Histogram biểu diễn hiệu suất hoạt động của các mẫu xe:
- Đường màu xanh thể hiện phân phối chuẩn (normal distribution) của dữ liệu.
- Các đường màu đỏ thể hiện ±2 độ lệch chuẩn từ giá trị trung bình. Có thể thấy rằng, những mẫu xe có hiệu suất chạy vượt trội (trên 14 km/l) thường nằm ngoài 2 độ lệch chuẩn so với mức trung bình của dữ liệu.
Vậy, cách tính Outlier là gì?
- Giá trị trung bình của dữ liệu = 8 km/l
- Độ lệch chuẩn (Standard Deviation) = 2 km/l
- Giới hạn xác định outlier được tính như sau.
Vậy ta nhận định rằng: Hầu hết các mẫu xe có hiệu suất hoạt động dao động quanh giá trị trung bình (mean) là khoảng 14 km/l. Các giá trị dưới 4 km/l và trên 12 km/l sẽ được coi là outlier ngoại lai.
2. Sử dụng Z-Score để phát hiện outlier ngoại lai
Z-Score là một chỉ số đo lường giá trị của một điểm dữ liệu so với giá trị trung bình của tập dữ liệu. Được tính theo đơn vị độ lệch chuẩn.
- Z-Score = 0 → Giá trị trùng với trung bình
- Z-Score = +2 → Giá trị cao hơn 2 độ lệch chuẩn so với trung bình
- Z-Score = -2 → Giá trị thấp hơn 2 độ lệch chuẩn so với trung bình
- Các điểm dữ liệu có Z-Score từ ± 3 trở lên được xem là ngoại lai. Vì chúng nằm ngoài vùng phân phối chuẩn.
Công thức tính Z-Score
Trong đó:
- X = Giá trị cần phân tích
- μ = Giá trị trung bình
- σ = Độ lệch chuẩn
Ví dụ: bạn đang phân tích doanh số bán pizza của Razza Pizza tại New Jersey trong năm 2015. Dữ liệu bán hàng được phân phối theo phân phối chuẩn. Và các thông số thống kê của doanh số bán hàng như sau:
- Giá trị trung bình (Mean) = 138
- Độ lệch chuẩn (Standard Deviation) = 24
- Một ngày có doanh số bán là 215 cái pizza
Áp dụng công thức Z-Score:
Doanh số 215 pizza là một giá trị ngoại lai vì nó nằm ngoài phạm vi 3 độ lệch chuẩn. Giá trị này cho thấy một ngày bán hàng cực kỳ thành công. Hoặc có thể là kết quả của một sự kiện đặc biệt. Chẳng hạn như khuyến mãi lớn hoặc ngày lễ.
3. Sử dụng Interquartile Range để xác định giới hạn của Outliers ngoại lai
Tiếp theo hãy cùng tìm hiểu phương pháp Interquartile Range (IQR) để xác định giới hạn của Outliers ngoại lai.
Phương pháp này dựa trên việc chia dữ liệu thành các phần tử tứ phân vị (interquartile). Và xác định khoảng cách giữa các phần tử để phát hiện các giá trị nằm ngoài quy luật chung.
Interquartile Range (IQR) là khoảng giá trị nằm giữa phần tử tứ phân vị thứ nhất (Q1) và phần tử tứ phân vị thứ ba (Q3). Cụ thể:
- Q1 (Quartile 1): Là giá trị của phần tử nằm ở vị trí 25% thấp nhất trong tập dữ liệu.
- Q3 (Quartile 3): Là giá trị của phần tử nằm ở vị trí 25% cao nhất trong tập dữ liệu.
- IQR = Q3 – Q1: Là khoảng cách giữa phần tử tứ phân vị thứ nhất và phần tử tứ phân vị thứ ba. Thể hiện mức độ phân tán của 50% dữ liệu nằm ở giữa.
Sau khi xác định giá trị Q1 và Q3, bạn có thể tính được các giá trị giới hạn để phát hiện giá trị ngoại lai theo công thức:
- Giới hạn dưới = Q1 – 1.5 × IQR
- Giới hạn trên = Q3 + 1.5 × IQR
- Nếu một giá trị nằm ngoài giới hạn dưới hoặc giới hạn trên, giá trị đó được coi là outlier.
- Nếu một giá trị nằm ngoài giới hạn nghiêm trọng(± 3 × IQR), giá trị đó được coi là outlier nghiêm trọng.
Quay lại với ví dụ về phân tích doanh số bán tại Razza Pizza. Dữ liệu doanh số được chia thành các phần tử tứ phân vị như sau:
- Q1: 124
- Q3: 150
- IQR = Q3 – Q1 = 150 – 124 = 26
a. Bước 1: Tính giới hạn dưới và giới hạn trên:
- Giới hạn dưới = 124 – (1.5 × 26) = 85
- Giới hạn trên = 150 + (1.5 × 26) = 189
b. Bước 2: Tính giới hạn ngoại lai nghiêm trọng (±3 IQR):
- Giới hạn dưới nghiêm trọng = 124 – (3 × 26) = 46
- Giới hạn trên nghiêm trọng = 150 + (3 × 26) = 228
c. Bước 3: Kết luận
- Nếu một ngày có doanh số bán pizza thấp hơn 85 hoặc cao hơn 189, thì đó là Outlier.
- Nếu doanh số thấp hơn 46 hoặc cao hơn 228, thì đó là giá trị ngoại lai nghiêm trọng.
IQR là phương pháp đơn giản, dễ tính toán. Và có thể áp dụng cho nhiều loại tập dữ liệu khác nhau. Khi kết hợp với biểu đồ Boxplot, IQR giúp trực quan hóa và xác định nhanh chóng các giá trị ngoại lai. Phương pháp IQR hiệu quả để phát hiện giá trị ngoại lai. Vì nó không yêu cầu dữ liệu phải tuân theo phân phối chuẩn. Khi phân phối dữ liệu có dạng bất thường hoặc bị lệch, phương pháp IQR vẫn có thể cho kết quả chính xác.
Tuy nhiên, phương pháp này có thể không chính xác khi kích thước tập dữ liệu nhỏ. Đồng thời kém hiệu quả nếu dữ liệu có xu hướng phân tán rộng và thiếu tính đồng nhất. Bên cạnh đó, phương pháp này cũng gặp khó khăn trong việc phát hiện các giá trị ngoại lai khi phân phối dữ liệu có nhiều cụm (clusters).
4. Sử dụng Hypothesis Tests để phát hiện Outlier ngoại lai
Phát hiện ngoại lai bằng phương pháp kiểm định giả thuyết (Hypothesis Test) là một cách tiếp cận hiệu quả trong phân tích dữ liệu. Đặc biệt khi dữ liệu tuân theo phân phối chuẩn. Kiểm định giả thuyết cho phép xác định xem một giá trị trong tập dữ liệu có khác biệt so với các giá trị còn lại hay không bằng cách so sánh với các giả thuyết thống kê.
Phương pháp kiểm định giả thuyết thông thường được thực hiện thông qua Grubbs’ Test, trong đó:
- Giả thuyết Null (H0): Tất cả các giá trị trong tập dữ liệu đều được lấy từ cùng một phân phối chuẩn.
- Giả thuyết Alternative (H1): Ít nhất một giá trị trong tập dữ liệu không tuân theo phân phối chuẩn. Và được coi là một giá trị ngoại lai.
Nếu p-value (giá trị xác suất) thấp hơn mức ý nghĩa thống kê (significance level), thì có thể bác bỏ giả thuyết null. Và kết luận rằng có sự tồn tại của một hoặc nhiều giá trị ngoại lai trong tập dữ liệu.
Giả sử bạn đang phân tích doanh số bán pizza của Razza Pizza tại New Jersey trong năm 2015 như trên.
Kết quả tính toán được:
- Giá trị Grubbs tính được = 5.22
- Giá trị tới hạn (critical value) = 3.77
Phân tích:
- Vì 5.22 > 3.77, ta có thể bác bỏ giả thuyết null (H0) và kết luận rằng tập dữ liệu có chứa một hoặc nhiều giá trị ngoại lai.
- Do đó, có ít nhất một ngày bán pizza có doanh số khác biệt đáng kể so với các ngày còn lại. Được coi là giá trị ngoại lai (outlier).
Dưới đây là các ngày có doanh số bán pizza được xác định là giá trị ngoại lai:
Sử dụng Grubbs’ Test đã xác định chính xác các giá trị ngoại lai trong tập dữ liệu của Razza Pizza. Tuy nhiên, vì các giá trị này liên quan đến các ngày lễ hoặc sự kiện đặc biệt. Chúng nên được giữ lại để phân tích xu hướng kinh doanh thay vì loại bỏ.
Grubbs’ Test đã xác định chính xác các giá trị ngoại lai trong tập dữ liệu của Razza Pizza. Tuy nhiên, vì các giá trị này liên quan đến các ngày lễ hoặc sự kiện đặc biệt, chúng nên được giữ lại để phân tích xu hướng kinh doanh thay vì loại bỏ.
Khi thực hiện kiểm định dữ liệu ngoại lai, bạn cần chọn quy trình dựa trên số lượng giá trị ngoại lai hoặc chỉ định số lượng giá trị ngoại lai cho quá trình kiểm định. Phương pháp kiểm định của Grubbs chỉ kiểm tra một giá trị ngoại lai. Trong khi đó, các phương pháp khác như kiểm định Tietjen-Moore Test sẽ yêu cầu bạn chỉ định một số lượng giá trị ngoại lai cụ thể.
Checklist 3 phương pháp xác định Outlier (Ngoại lai)
| Phương pháp | Mô tả nhanh | Khi nào áp dụng? | Ưu điểm | Hạn chế |
|---|---|---|---|---|
| 1. Mean ± Standard Deviation | Xác định giá trị nằm ngoài khoảng ±2 hoặc ±3 lần độ lệch chuẩn | Khi dữ liệu tuân theo hoặc gần với phân phối chuẩn (normal distribution) | Dễ áp dụng, trực quan, tính toán nhanh | Không hiệu quả nếu dữ liệu phân phối lệch hoặc có nhiều cụm |
| 2. Z-Score | Tính điểm chuẩn hóa cho từng giá trị, đánh giá độ lệch so với giá trị trung bình | Khi dữ liệu gần chuẩn hóa, và bạn muốn định lượng độ lệch cụ thể | Chuẩn xác, có ngưỡng xác định rõ (±3) | Không hiệu quả với dữ liệu lệch mạnh, nhiều biến số, hoặc không chuẩn hóa |
| 3. IQR (Interquartile Range) | Xác định outlier dựa trên khoảng giữa Q1 và Q3 (±1.5×IQR hoặc ±3×IQR) | Khi dữ liệu không theo phân phối chuẩn hoặc bị lệch; đặc biệt hữu ích với biểu đồ boxplot | Không yêu cầu dữ liệu chuẩn, áp dụng linh hoạt, dễ trực quan hóa | Có thể kém chính xác nếu dữ liệu nhỏ, phân tán rộng, hoặc có nhiều cụm (clusters) |
VII. Tạm kết
Outlier không chỉ đơn thuần là những điểm dữ liệu bất thường mà còn là tín hiệu quan trọng giúp doanh nghiệp và nhà phân tích phát hiện sai sót, rủi ro hoặc cơ hội tiềm năng. Loại bỏ những điểm dữ liệu ngoại lai outlier là một phần quan trọng trong quá trình làm sạch dữ liệu. Để đảm bảo những phân tích đầu ra chính xác và đưa ra những đề xuất, quyết định kinh doanh có thể áp dụng.
Bài viết trên đã giúp bạn hiểu thêm về Outlier là gì và các tips để xử lí Outlier nhanh chóng, hiệu quả nhất. Tuy nhiên, để có thể hiểu Outlier là gì và vận dụng đúng các phương pháp để xác định Outlier nói riêng, và xử lí dữ liệu nói chung, thì sẽ cần bạn phải có đầy đủ kĩ năng và kiến thức về công cụ phân tích dữ liệu.
Khoá học Phân tích dữ liệu Data for Business Professionals tại ACE Academy
Nếu bạn muốn nâng cao kĩ năng và tư duy làm việc, xử lý, phân tích dữ liệu để tìm ra các insight ẩn, phát hiện vấn đề, tránh đưa ra các quyết định cảm tính, tham khảo ngay Khoá học Phân tích dữ liệu Data for Business Professionals tại ACE Academy. Khóa học sẽ trang bị cho bạn một lộ trình phân tích dữ liệu chuẩn chỉnh. Hoàn thành khóa học bạn sẽ có đầy đủ kỹ năng xử lí dữ liệu, xây dựng dashboard, phân tích chiến lược để tìm ra insight hữu ích, nâng cao thêm nhiều kĩ năng data storytelling, trực quan hóa và kể câu chuyện dữ liệu thú vị. Nếu bạn đang tìm kiếm khóa học với nhiều case study và project thực tế, đây cũng là sự lựa chọn tuyệt vời cho bạn.
Bắt đầu hành trình của bạn ngay hôm nay với các khóa học của ACE Academy để trở thành một chuyên gia phân tích dữ liệu thành công!

FAQ – Câu hỏi thường gặp về outlier – ngoại lai là gì?
1. Outlier – dữ liệu ngoại lai trong dữ liệu là gì?
2. Khi nào cần loại bỏ outlier trong phân tích dữ liệu?
3. Cách phát hiện outlier (ngoại lai) đơn giản nhất là gì?
4. Outlier ảnh hưởng thế nào đến mô hình học máy?
5. Có nên loại bỏ hoàn toàn outlier không?












